
Key Takeaways
- PlayHT is shutting down on December 31, 2025 — the company announced retirement of all services including Studio, API, and Voice Agents
- PlayHT generates human-like AI voices in under 800 milliseconds with emotional control and real-time voice cloning
- The platform supports 800+ AI voices across 142+ languages with instant voice cloning from just 3 seconds of audio
- Current subscribers retain full access through the shutdown date, but no new sign-ups are accepted
- Alternative solution: Gaga AI offers similar text-to-speech capabilities for users planning their migration
Table of Contents
What Is PlayHT?
PlayHT is a California-based AI voice generation platform that converts written text into natural-sounding human speech using advanced neural voice technology. Founded in 2016 by Mahmoud Felfel and Syed Hammad Ahmed, the company evolved from a simple Chrome extension for Medium articles into a comprehensive voice synthesis solution serving global enterprises including Amazon, RedBull, and Volvo.
The platform operates with distributed teams across the United States and India, focusing on scalable audio content production without traditional voiceover requirements. Play.ht offers three core products: the web-based Studio interface, a developer-focused API, and Voice Agents for conversational AI applications.
Current Status: As of the December 2025 announcement, PlayHT is winding down operations. The company will cease all services on December 31, 2025, giving existing users time to complete projects and transition to alternative platforms.
How Does Play.ht Studio Work?
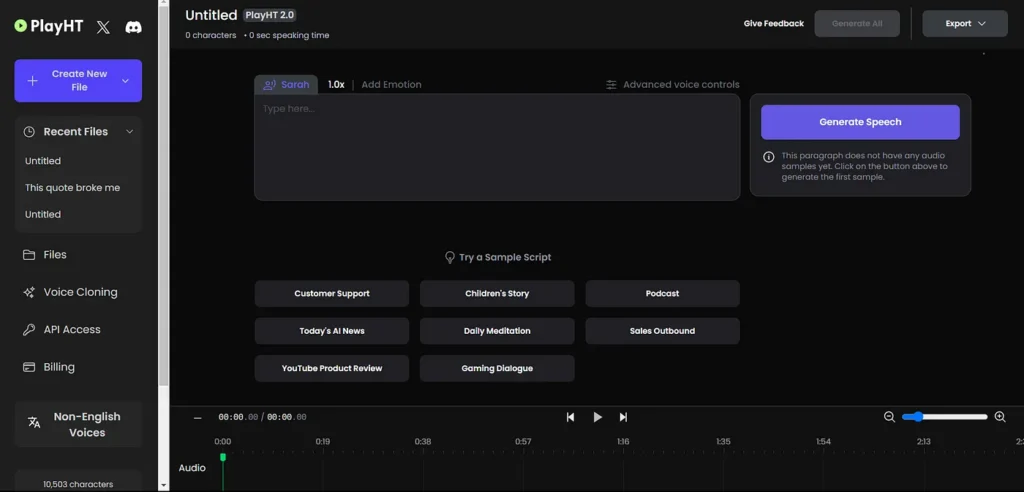
Play.ht Studio is a web-based editor that transforms text into audio through a four-step process: text input, voice selection, customization, and export. The platform processes text using generative AI models trained on extensive speech datasets to produce natural-sounding voiceovers.
The Voice Generation Process
1. Input your content — Paste text directly, upload documents, or integrate with platforms like WordPress, Google Docs, and Notion
2. Select from 800+ voices — Choose voices by language, accent, gender, age, and emotional tone across 142 supported languages
3. Customize delivery — Adjust speed, pitch, emphasis, pauses, and pronunciation using SSML (Speech Synthesis Markup Language) controls
4. Generate and export — Create audio in real-time with latency under 1 second, then download in MP3, WAV, or other formats
The Studio interface provides real-time preview capabilities, allowing users to test different voices and settings before final generation. Multi-voice support enables dialogue creation with distinct speakers in a single audio file.
Key Features of PlayHT AI
Voice Cloning Technology
PlayHT’s instant voice cloning replicates any voice from just 3 seconds of audio input without fine-tuning. The platform uses generative voice AI models to capture unique vocal characteristics including accent, tone, pitch, and speaking patterns. Cross-language cloning preserves the original speaker’s voice characteristics while generating speech in different languages.
Emotional Voice Generation
The PlayHT 2.0 model introduced emotion-aware voice synthesis that understands and applies emotional context in real-time. Users can direct AI-generated speech with specific emotions including:
- Joy and enthusiasm
- Sadness and empathy
- Surprise and excitement
- Anger and frustration
- Neutral professional tone
This emotional control operates without pre-recorded emotion samples, allowing dynamic adjustment during generation.
Real-Time Conversion Capabilities
PlayHT processes text-to-speech conversion in under 800 milliseconds, enabling real-time applications like:
- Live conversational AI agents
- Interactive voice response (IVR) systems
- Real-time translation and dubbing
- Streaming podcast generation
- Dynamic audio content for apps
The low-latency performance makes play.ht suitable for applications requiring immediate audio feedback without noticeable delays.
Multi-Voice Conversations
The platform supports multi-speaker dialogue within single audio files, essential for:
- Podcast episode creation with multiple hosts
- Audiobook narration with character voices
- Educational content with instructor-student exchanges
- Corporate training materials
- Interview-style content
Users assign different voices to specific text segments, creating natural conversational flow without manual audio editing.
PlayHT vs. Traditional Voice Recording
Cost Comparison
Traditional voiceover production costs $100-500 per finished minute, including:
- Voice talent fees ($200-400/hour for professionals)
- Studio rental ($50-150/hour)
- Audio engineering and editing ($50-100/hour)
- Multiple revision rounds
PlayHT premium plans range from $31-99/month for unlimited generation, reducing per-minute costs to under $1 for high-volume users.
Production Speed
Traditional recording requires 2-5 business days for:
- Script review and talent briefing
- Recording session scheduling
- Studio time and multiple takes
- Post-production editing
- Revision cycles
Play.ht generates finished audio in seconds, enabling same-day content production and rapid iteration without scheduling constraints.
Scalability Advantages
AI voice generation scales infinitely without additional cost per unit. Organizations producing 100+ audio assets monthly achieve 90% cost reduction and 95% time savings compared to traditional methods.
Integration Capabilities
Content Platform Integrations
PlayHT connects directly with major content platforms through:
- WordPress plugin — Add audio players to blog posts automatically
- Google Docs add-on — Convert documents to audio without leaving Google Workspace
- Notion integration — Generate audio from Notion pages
- Medium Chrome extension — One-click audio addition to Medium articles
Automation Tools
Zapier integration enables automated workflows such as:
- Auto-generate audio when new blog posts publish
- Create audio versions of email newsletters
- Convert RSS feed updates to podcast episodes
- Trigger voice generation from Airtable updates
Developer API Access
The PlayHT API provides:
- RESTful endpoints for text-to-speech conversion
- WebSocket support for streaming audio
- Voice cloning API endpoints
- Comprehensive documentation and SDKs
- 99.9% uptime SLA for enterprise plans
How to Transition from PlayHT
Recommended Alternative: Gaga AI
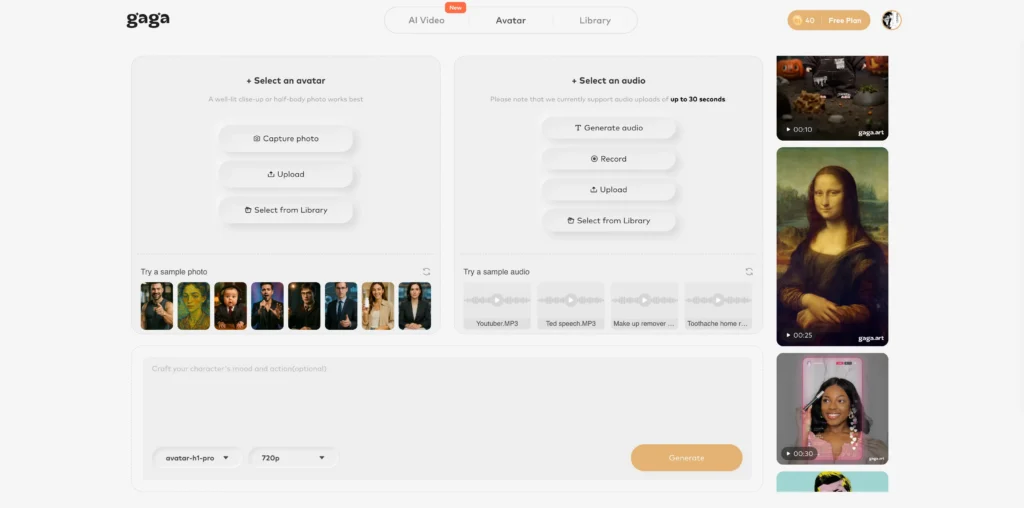
Gaga AI offers comparable text-to-speech capabilities with:
- 500+ AI voices across 100+ languages
- Instant voice cloning technology
- Emotional voice control
- API access for developers
- Similar pricing structure
Migration Checklist
Before December 31, 2025, PlayHT users should:
1. Export all generated audio files — Download MP3/WAV files of important voice content before service termination
2. Document voice settings — Record custom pronunciation dictionaries, SSML configurations, and voice preferences
3. Archive voice clones — Save voice clone models and training audio for potential recreation on new platforms
4. Update integrations — Remove PlayHT API calls from production applications and replace with alternative providers
5. Notify stakeholders — Inform team members and clients about the platform change
6. Test alternatives thoroughly — Evaluate Gaga AI or other TTS platforms before migrating production workflows
Other Text-to-Speech Alternatives
Beyond Gaga AI, consider these options:
ElevenLabs — Premium voice synthesis with emphasis on emotional range and natural prosody. Higher pricing than PlayHT but excellent voice quality.
Murf.ai — Business-focused platform with collaborative features for team projects. Strong suit: professional voiceovers for corporate content.
WellSaid Labs — Enterprise-grade TTS with focus on brand voice consistency. Best for: large organizations needing custom voice development.
Amazon Polly — AWS cloud-based service with pay-as-you-go pricing. Ideal for: developers already using AWS infrastructure.
Google Cloud Text-to-Speech — Neural voices through Google Cloud Platform. Best for: applications requiring tight integration with Google services.
Open-Source Text-to-Speech Alternatives for Developers
Text-to-Speech (TTS) technology converts written text into human-understandable speech signals through various algorithms and neural networks. While commercial platforms like PlayHT offer premium features, developers and technical users have access to powerful open-source TTS libraries for custom implementations.
Why Consider Open-Source TTS Libraries?
Open-source text-to-speech solutions provide several advantages:
- No subscription costs — Free to use, modify, and distribute
- Complete control — Host on your own infrastructure without third-party dependencies
- Privacy protection — Process sensitive content locally without cloud transmission
- Customization flexibility — Modify source code for specific requirements
- No usage limits — Generate unlimited audio without character count restrictions
- Offline capability — Function without internet connectivity
These libraries serve as foundational tools for building voice interaction applications, learning speech synthesis technology, and creating text-to-speech projects without commercial constraints.
Top Open-Source TTS Libraries
1. eSpeak NG
eSpeak NG is a lightweight, open-source speech synthesis engine supporting numerous languages. This compact library excels in multilingual applications where resource efficiency matters more than natural voice quality.
- Strengths: Small footprint, fast processing, extensive language support (100+ languages)
- Limitations: Robotic voice quality compared to neural TTS
- Best for: Embedded systems, accessibility tools, language learning apps
- Technical requirements: Minimal system resources, runs on Raspberry Pi
2. Festival
Festival is a general-purpose speech synthesis system developed by Carnegie Mellon University, supporting English and select additional languages. The system provides comprehensive text analysis and waveform generation capabilities.
- Strengths: Mature codebase, academic backing, extensible architecture
- Limitations: Older technology, limited modern voice quality
- Best for: Research projects, educational environments, legacy system integration
- Technical requirements: Linux-friendly, C++ programming knowledge helpful
3. MaryTTS
MaryTTS is an open-source speech synthesis platform developed collaboratively by DFKI, University of Zurich, and University of Tübingen, offering multilingual support through modular architecture.
- Strengths: Java-based for cross-platform compatibility, SSML support, multiple languages
- Limitations: Requires Java runtime environment, heavier resource usage
- Best for: Enterprise applications, web services, educational institutions
- Technical requirements: Java 8+, moderate system resources
4. Mimic
Mimic is an open-source text-to-speech system developed by Mycroft AI that generates natural human-like speech suitable for voice assistant applications.
- Strengths: Designed for conversational AI, actively maintained, neural voice options
- Limitations: Smaller voice library than commercial solutions
- Best for: Smart home assistants, IoT devices, conversational interfaces
- Technical requirements: Python environment, TensorFlow for neural voices
5. Flite (Festival Lite)
Flite is a small, fast-running, open-source speech synthesis engine developed by Carnegie Mellon University, optimized for embedded and mobile applications.
- Strengths: Extremely lightweight (under 2MB), fast execution, portable
- Limitations: Basic voice quality, limited customization
- Best for: Mobile apps, embedded devices, real-time applications with constraints
- Technical requirements: Minimal dependencies, C language integration
6. gTTS (Google Text-to-Speech)
gTTS is a Python library providing Google Text-to-Speech API access without complex installation requirements, offering straightforward text-to-audio conversion.
- Strengths: Simple Python interface, leverages Google’s quality, minimal setup
- Limitations: Requires internet connectivity, subject to Google’s rate limits
- Best for: Quick prototyping, Python scripts, non-commercial projects
- Technical requirements: Python 3.x, internet connection
7. pyttsx3
pyttsx3 is a cross-platform Python text-to-speech library utilizing platform-native engines (SAPI5 on Windows, NSSpeechSynthesizer on macOS, eSpeak on Linux).
- Strengths: Offline functionality, no dependencies, works across operating systems
- Limitations: Voice quality depends on system engines, limited customization
- Best for: Desktop applications, offline tools, rapid development
- Technical requirements: Python 3.x, no additional libraries needed
8. ResponsiveVoice
ResponsiveVoice is a pure JavaScript speech synthesis library supporting multiple languages with natural-sounding voices through browser-based implementation.
- Strengths: No server requirements, client-side processing, web-ready
- Limitations: Requires modern browser support, dependent on browser TTS engines
- Best for: Web applications, interactive websites, browser-based tools
- Technical requirements: Modern web browser with Web Speech API support
Choosing Between Open-Source and Commercial TTS
Decision factors for selecting open-source versus commercial text-to-speech solutions:
Choose Open-Source When:
- Budget constraints prohibit subscription costs
- Data privacy requires local processing
- Customization needs exceed commercial platform capabilities
- Offline functionality is essential
- Project serves educational or research purposes
- Development team has technical expertise for implementation
Choose Commercial Platforms (like PlayHT, Gaga AI) When:
- Voice quality and naturalness are paramount
- Rapid deployment without technical overhead is needed
- Extensive voice variety across languages is required
- Emotional expression and advanced features matter
- Reliable support and maintenance are necessary
- Time-to-market is critical
For developers building production applications, hybrid approaches combining open-source libraries for basic functionality and commercial APIs for premium features often provide optimal balance.
Is PlayHT Better Than ElevenLabs?
PlayHT and ElevenLabs both deliver high-quality AI voices, but they serve different priorities. PlayHT emphasizes speed (under 800ms generation), extensive language support (142 languages), and affordable unlimited plans. ElevenLabs focuses on emotional depth, voice expressiveness, and premium natural-sounding output.
Feature Comparison
Voice Quality:
- PlayHT 2.0 produces conversational speech optimized for real-time applications
- ElevenLabs excels at narration, audiobooks, and content requiring emotional nuance
- Both platforms pass casual listening tests for realism
Voice Cloning Speed:
- PlayHT: Instant cloning from 3 seconds of audio without fine-tuning
- ElevenLabs: Requires 1-5 minutes of training audio for professional voice cloning
- PlayHT wins for rapid prototyping; ElevenLabs delivers higher fidelity for final production
Pricing:
- PlayHT offered unlimited generation at $99/month (pre-shutdown)
- ElevenLabs charges based on character count with 30,000 characters/month at $22
- For high-volume users, PlayHT provided better value
Use Case Fit:
- Choose PlayHT for: real-time conversational AI, multilingual content at scale, budget-conscious projects
- Choose ElevenLabs for: audiobooks, premium podcasts, content where voice quality is paramount
Given PlayHT’s shutdown, ElevenLabs emerges as the premium alternative for users prioritizing voice quality over cost.
Frequently Asked Questions (FAQ)
What is PlayHT and what does it do?
PlayHT is an AI-powered text-to-speech platform that converts written content into natural-sounding human voice audio. The service uses neural voice generation technology to produce realistic speech in 800+ voices across 142 languages. Users input text through a web interface or API, select voice preferences, and receive audio files within seconds. The platform served content creators, developers, educators, and enterprises needing scalable voiceover solutions.
Is PlayHT shutting down permanently?
Yes, PlayHT announced permanent closure effective December 31, 2025. The company will retire all products including play.ht studio, the API, and Voice Agents. Current subscribers maintain access through the shutdown date, but new sign-ups are no longer accepted. Users should complete active projects and migrate to alternative platforms like Gaga AI, ElevenLabs, or Murf.ai before the termination date.
Can I still use PlayHT after December 2025?
No, all PlayHT services become inaccessible after December 31, 2025. This includes the web application, API endpoints, voice clones, and any hosted audio files. Users must download generated audio, export voice clone data, and remove API integrations before this deadline. The company has not announced plans to open-source the technology or provide legacy access.
How much does PlayHT cost?
PlayHT offered four pricing tiers before shutdown: Free plan (12,500 characters/month), Creator ($31/month for 300,000 characters), Pro ($75/month for 1M characters), and Enterprise (custom pricing). Commercial usage rights came with paid plans. Character counts include all text processed, with spaces and punctuation excluded from calculation. Annual subscriptions received 20% discounts.
What is the best PlayHT alternative?
Gaga AI represents the closest PlayHT alternative with comparable features and pricing. The platform offers 500+ voices, instant voice cloning, emotional control, and API access at similar price points. For premium voice quality, ElevenLabs excels despite higher costs. Budget users might consider Google Cloud Text-to-Speech or Amazon Polly for pay-per-use models. Developers already using specific cloud providers should explore native TTS services for easier integration.
How does PlayHT voice cloning work?
PlayHT’s instant voice cloning requires just 3 seconds of audio to replicate a voice. Users record themselves speaking naturally, upload the audio file, and the AI analyzes vocal characteristics including pitch, rhythm, tone, and accent. The system generates a voice model usable immediately without training delays. Professional-grade clones benefit from 5-10 minutes of varied speech samples. The technology works across languages, preserving the speaker’s voice while generating speech in different languages.
Can PlayHT generate emotional voices?
Yes, playht ai includes emotional voice generation through PlayHT 2.0 models. Users can specify emotions including happiness, sadness, anger, surprise, and neutral tones. The system applies emotional context during generation rather than requiring pre-recorded emotional samples. Emotional intensity is adjustable, allowing subtle mood shifts or dramatic expression. This feature enables more engaging content for storytelling, marketing, and conversational AI applications.
Does PlayHT support commercial use?
Commercial usage rights are included with PlayHT Creator, Pro, and Enterprise plans. Users could legally use generated audio in YouTube videos, podcasts, advertisements, online courses, audiobooks, and client projects. The free plan restricted usage to personal, non-commercial applications. Voice cloning required permission from the original speaker for commercial deployment. Audio generated before shutdown retains commercial rights per the original license terms.
What file formats does PlayHT export?
Play.ht studio exports audio in MP3, WAV, OGG, and FLAC formats. MP3 provides smallest file sizes suitable for web delivery and streaming. WAV offers uncompressed quality for professional editing. OGG balances quality and compression for web applications. FLAC delivers lossless compression for archival purposes. Sample rates range from 8kHz (phone quality) to 48kHz (studio quality). Bitrates adjust automatically or manually up to 320kbps for MP3.
How fast is PlayHT voice generation?
PlayHT generates conversational speech in under 800 milliseconds from text submission to audio delivery. This low latency enables real-time applications like voice assistants and live translation. Longer scripts (1000+ words) process incrementally with first audio chunks available in under 1 second. API streaming endpoints deliver audio as generated rather than waiting for complete file. Processing speed varies by voice model complexity and server load but remains under 2 seconds for 95% of requests.
Can I integrate PlayHT with my website?
Yes, PlayHT offered multiple integration methods. Direct embed codes placed audio players on web pages. WordPress plugins added TTS functionality to blog posts. Google Docs and Notion integrations generated audio from documents. The API enabled custom implementations in any programming language. Zapier connections automated voice generation from various triggers. Most integrations required paid plans and API keys for authentication.
Is PlayHT better than Google Text-to-Speech?
PlayHT offered superior voice naturalness and customization compared to Google Cloud Text-to-Speech. PlayHT voices sounded more human-like with better prosody and emotional range. The web interface required no coding knowledge, while Google TTS demands API implementation. However, Google TTS provides better enterprise scalability, integration with Google services, and pay-per-use pricing beneficial for low-volume users. PlayHT suited content creators; Google TTS served developers and enterprises.
Related Posts:
 Google Veo 3: The Complete Guide to Features, Pricing, and the Best Alternative – Gaga AI & Sora 2
Google Veo 3: The Complete Guide to Features, Pricing, and the Best Alternative – Gaga AI & Sora 2
 Suno AI Music Generator: The Complete Guide to AI Music Generation in 2026
Suno AI Music Generator: The Complete Guide to AI Music Generation in 2026
 Ultimate Natural Reader Guide: Top 5 AI Text to Speech Tools in 2026
Ultimate Natural Reader Guide: Top 5 AI Text to Speech Tools in 2026
 PixVerse AI Review 2026: Features, Pricing & Best Alternatives
PixVerse AI Review 2026: Features, Pricing & Best Alternatives


