
Key Takeaways
- GPT-5.4 is OpenAI’s most capable and efficient frontier model for professional work, released on March 5, 2026.
- It combines elite coding ability (on par with GPT-5.3-Codex) with superior world knowledge and reasoning — the first model to do both.
- GPT-5.4 is the first general-purpose model with native computer-use capabilities, letting AI agents operate desktop and web apps like a human.
- It supports up to 1 million tokens of context, enabling long-horizon agentic tasks.
- On GDPval, GPT-5.4 matches or beats industry professionals in 83% of real-world knowledge work comparisons.
- Available now for ChatGPT Plus, Team, and Pro users as GPT-5.4 Thinking, and in the API as gpt-5.4.
Table of Contents
What Is GPT-5.4?
GPT-5.4 is OpenAI’s latest and most advanced reasoning model, designed specifically for demanding professional work. It merges the industry-leading coding strengths of GPT-5.3-Codex with the broad world knowledge and reasoning of the GPT-5.2 series — and adds native computer-use capabilities on top.
In plain English: previous models could tell you how to do something. GPT-5.4 can actually do it — navigating websites, filling out forms, editing spreadsheets, and operating desktop software, all on its own.
OpenAI calls it “our most capable and efficient frontier model for professional work,” and the benchmarks back that up.
Why GPT-5.4 Is a Big Deal: The Wall It Breaks Down
Before GPT-5.4, there was an invisible wall between AI and real work. You could ask a model to analyze a competitor — it would write a text report. You could ask it to automate Excel — it would hand you Python code to run yourself. You could ask it to book a flight — it would describe which buttons to click.
That wall was called computer operation.
GPT-5.4 tears it down. It can see your screen via screenshots, issue mouse and keyboard commands, and chain actions across multiple applications. This isn’t a separate plugin or extra API call — it’s built directly into the model itself.
That “native” distinction matters enormously for developers and enterprises. Lower latency, more natural task handoffs, less glue code, and faster deployment.
GPT-5.4 Benchmark Performance: How It Compares
Here’s how GPT-5.4 stacks up against its predecessors across the most important benchmarks:
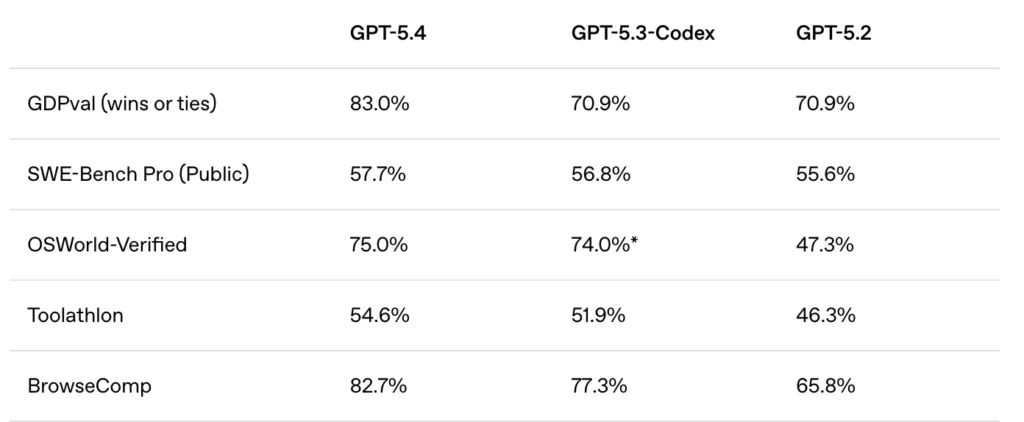
The story these numbers tell: GPT-5.4 doesn’t sacrifice one strength for another. It holds GPT-5.3-Codex’s coding ability while leaping ahead in knowledge work, computer use, and tool use.
What’s New in GPT-5.4: Feature Breakdown
1 Million Token Context Window
GPT-5.4 supports up to 1 million tokens of context in Codex and the API — more than double its predecessor’s window. This is critical for agentic tasks where the model must track a long chain of decisions, files, and tool outputs without losing the thread.
Note: In Codex, requests exceeding the standard 272K context count against usage limits at 2× the normal rate.
Native Computer Use
GPT-5.4 is OpenAI’s first general-purpose model with built-in computer-use capabilities. It can:
- Write code using Playwright and similar libraries to automate browsers and desktop apps
- Issue mouse and keyboard commands based on real-time screenshot analysis
- Complete multi-step workflows across multiple software environments
- Let developers configure its behavior and safety confirmation policies for their specific use case
On OSWorld-Verified — which tests a model’s ability to navigate a desktop purely through screenshots and keyboard/mouse actions — GPT-5.4 achieves a 75.0% success rate, surpassing the human performance baseline of 72.4% and far exceeding GPT-5.2’s 47.3%.
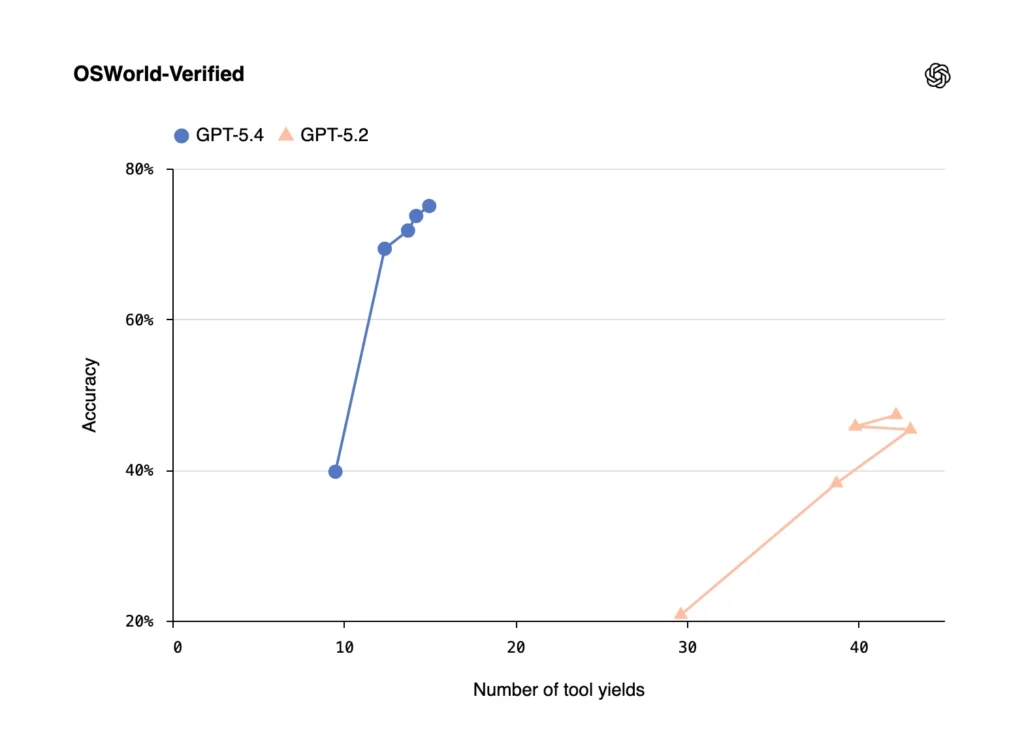
On WebArena-Verified (browser use), GPT-5.4 hits 67.3%. On Online-Mind2Web, it achieves 92.8% using only screenshots.
Knowledge Work: Matching Industry Professionals
On GDPval — a new evaluation that tests model performance on 44 real-world occupational tasks spanning finance, law, healthcare, engineering, and more — GPT-5.4 matches or exceeds industry professionals in 83% of comparisons. GPT-5.2 scored 70.9% on the same benchmark.
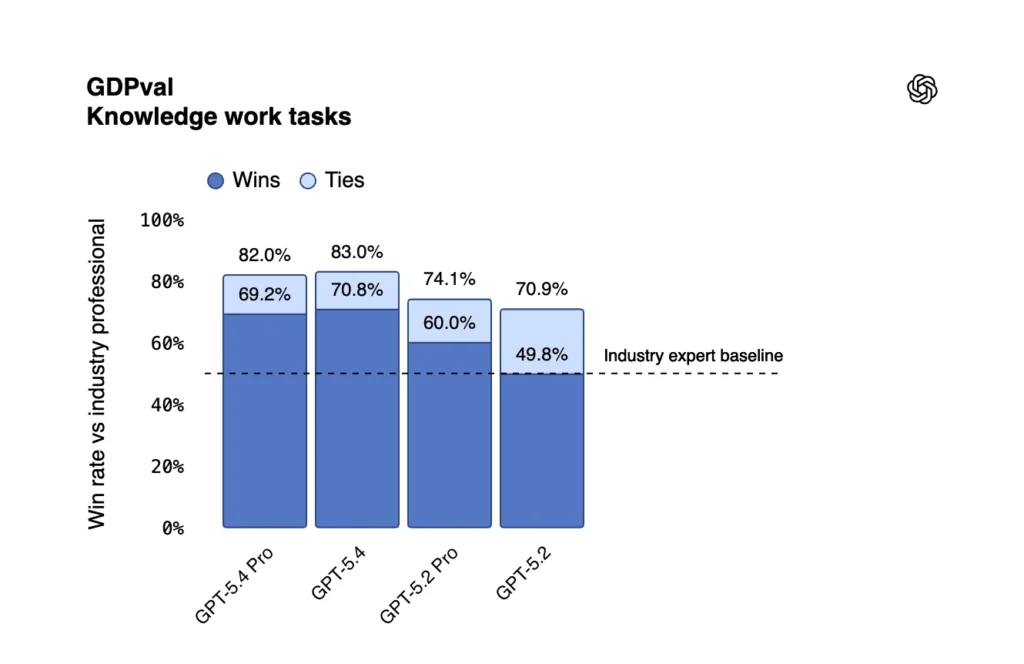
Specific improvements include:
- Spreadsheets: On internal investment banking modeling tasks, GPT-5.4 scores 87.3% vs. GPT-5.2’s 68.4%.
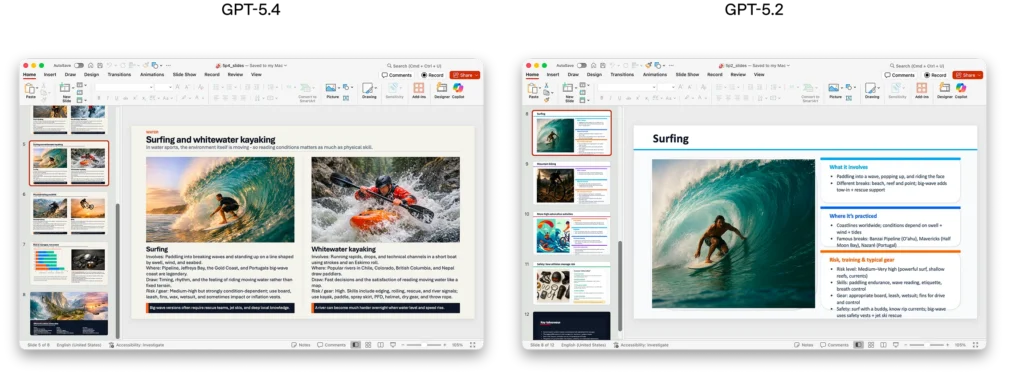
- Presentations: Human raters preferred GPT-5.4’s slides 68% of the time over GPT-5.2’s, citing stronger aesthetics, more visual variety, and better image use.
- Factual accuracy: GPT-5.4’s individual claims are 33% less likely to be false, and full responses are 18% less likely to contain any errors compared to GPT-5.2.
Improved Coding: Best of Both Worlds
GPT-5.4 absorbs GPT-5.3-Codex’s coding strengths while becoming significantly more capable in everything else. On SWE-Bench Pro, GPT-5.4 matches GPT-5.3-Codex (57.7% vs. 56.8%) while running at lower latency across reasoning effort levels.
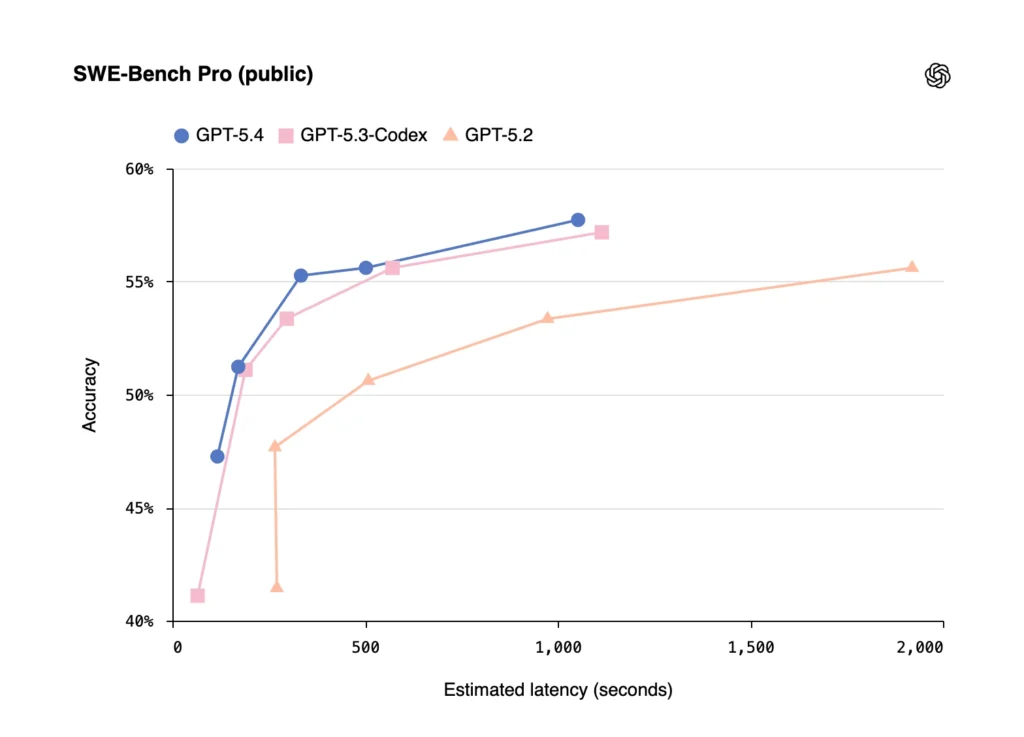
In Codex, /fast mode delivers up to 1.5× faster token velocity — same intelligence, just faster.
A new experimental Codex skill called “Playwright (Interactive)“ lets Codex visually debug web and Electron apps in real time, even testing an app as it’s building it.
Tool Search: 47% Fewer Tokens
Previously, giving a model access to many tools meant dumping all their definitions into the prompt upfront — potentially tens of thousands of wasted tokens per request.
GPT-5.4 introduces tool search: instead of loading all tool definitions at once, the model receives a lightweight list of available tools and looks up definitions on demand.
In OpenAI’s testing across 250 tasks with all 36 MCP servers enabled, tool search reduced total token usage by 47% while maintaining the same accuracy. For enterprises running large MCP ecosystems, the cost and latency savings are substantial.
Steerability: Mid-Response Guidance
GPT-5.4 Thinking in ChatGPT now provides an upfront plan of its thinking before starting. You can add instructions or adjust its direction mid-response — without starting over or burning extra turns.
This feature is live on chatgpt.com and Android, coming soon to iOS.
Improved Web Research
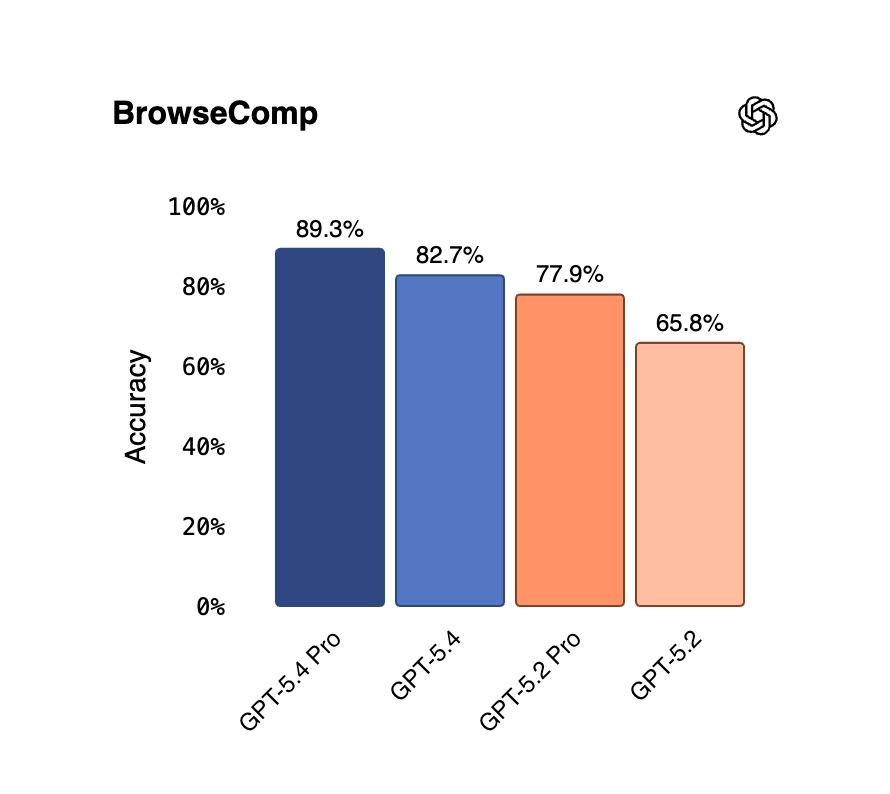
On BrowseComp — which measures how well AI agents can persistently browse the web to locate hard-to-find information — GPT-5.4 jumps 17 percentage points over GPT-5.2 (82.7% vs. 65.8%). The Pro variant hits 89.3%, a new state of the art.
GPT-5.4 vs. GPT-5.2 vs. GPT-5.3-Codex: Which Should You Use?
This is the practical question most developers and professionals actually care about.
Choose GPT-5.4 if:
- You need a single model that handles both code and professional knowledge work
- You’re building AI agents that operate computers or web browsers
- You’re working with complex multi-tool workflows or large MCP ecosystems
- You want the best balance of capability, speed, and token efficiency
Choose GPT-5.3-Codex if:
- Your workload is almost entirely software engineering
- You’re running tasks specifically in Codex
- You need the fastest possible speeds for coding iteration (though GPT-5.4 in fast mode is comparable)
Stick with GPT-5.2 if:
- You’re on a tight API budget and your tasks don’t require GPT-5.4’s specific improvements
- You’re already happy with your current performance on non-agentic tasks
The verdict for most professional use cases: GPT-5.4 is simply the better all-around model. It does what GPT-5.3-Codex does in code, and everything GPT-5.2 does in knowledge work — and it actually speaks plainly, which turns out to matter enormously for usability.
GPT-5.4 Pricing and Availability
ChatGPT
- GPT-5.4 Thinking is available to Plus, Team, and Pro users starting now, replacing GPT-5.2 Thinking.
- GPT-5.2 Thinking remains available for three months in the model picker under “Legacy Models,” retiring June 5, 2026.
- Enterprise and Edu plans can enable early access via admin settings.
- GPT-5.4 Pro is available to Pro and Enterprise plan users.
API Pricing
| Model | Input | Cached Input | Output |
| gpt-5.2 | $1.75 / M tokens | $0.175 / M tokens | $14 / M tokens |
| gpt-5.4 | $2.50 / M tokens | $0.25 / M tokens | $15 / M tokens |
| gpt-5.2-pro | $21 / M tokens | — | $168 / M tokens |
| gpt-5.4-pro | $30 / M tokens | — | $180 / M tokens |
Batch and Flex pricing are available at half the standard API rate. Priority processing is available at 2× the standard rate.
GPT-5.4’s improved token efficiency means many tasks will actually require fewer tokens than GPT-5.2, partially offsetting the higher per-token price.
GPT-5.4 Safety: What OpenAI Built In
OpenAI treats GPT-5.4 as High capability under its Preparedness Framework for both Cybersecurity and Biological/Chemical domains — meaning it has the corresponding safeguards in place.
Key safety features:
- Factual accuracy: 33% fewer false claims per response compared to GPT-5.2
- Chain-of-Thought monitorability: GPT-5.4’s reasoning traces remain interpretable and transparent
- CoT controllability is low — meaning the model cannot deliberately hide or obscure its reasoning from safety monitors, which OpenAI flags as a positive property
- Expanded cyber safety stack: includes monitoring systems, trusted access controls, and asynchronous blocking for high-risk requests on Zero Data Retention surfaces
- Prompt injection resistance significantly improved for connectors (0.998 vs. 0.979 for GPT-5.2)
Apollo Research’s independent evaluation found an overall deceptive behavior rate of ~1% in no-nudge settings, with no instances of covert subversion against developers observed.
Real-World Professional Reactions
Early enterprise testers have been vocal:
“GPT-5.4 is the best model we’ve ever tried. It excels at creating long-horizon deliverables such as slide decks, financial models, and legal analysis.” — Brendan Foody, CEO at Mercor
“GPT-5.4 xhigh is the new state of the art for multi-step tool use. GPT-5.4 finished the job where previous models gave up.” — Wade, CEO at Zapier
Walleye Capital reported a 30-percentage-point improvement in Excel financial modeling accuracy in internal testing.
One independent developer note worth flagging: some early testers reported occasional cases where the model executed tasks incorrectly but didn’t clearly flag the error. As with any autonomous agent, verifying outputs on high-stakes workflows remains important.
How to Get Started with GPT-5.4
In ChatGPT
- Log in to chatgpt.com with a Plus, Team, or Pro subscription.
- Open the model selector and choose GPT-5.4 Thinking.
- For spreadsheet tasks, check out the new ChatGPT for Excel add-in (available for Enterprise customers).
In the API
Use the model string gpt-5.4 for standard access or gpt-5.4-pro for maximum performance.
Enable tool search by configuring your MCP servers to sit behind the tool search layer rather than loading all definitions upfront — this alone can cut token costs by nearly half.
For computer-use tasks, use the updated computer tool in the API. OpenAI’s documentation includes recommended best practices for original and high image detail settings, which improve localization and click accuracy significantly.
In Codex
GPT-5.4 is the new default model in Codex. Enable /fast mode for up to 1.5× faster token velocity on coding tasks. Try the new Playwright (Interactive) skill for visual debugging of web and Electron apps.
To experiment with the 1M context window, configure model_context_window and model_auto_compact_token_limit in your Codex settings (note the 2× usage rate beyond 272K tokens).
GDPval: The New Standard for Real-World AI Performance
One of the major announcements alongside GPT-5.4 is the introduction of GDPval — a new benchmark OpenAI built to measure model performance on real-world, economically valuable tasks.
GDPval spans 44 occupations across 9 industries (finance, healthcare, law, manufacturing, tech, and more), with 1,320 specialized tasks created and vetted by professionals averaging 14 years of experience. Unlike academic benchmarks, GDPval tasks include actual deliverables: spreadsheets, slide decks, legal briefs, engineering diagrams, and more.
GPT-5.4 achieves 83.0% on GDPval — meaning it produces outputs that match or beat experienced industry professionals in over four out of five comparisons. For reference, GPT-4o (released spring 2024) scored around 12% on the same benchmark. Performance more than doubled from GPT-5.2 to GPT-5.4 in just months.
OpenAI is releasing a gold subset of GDPval tasks publicly and a grading service at evals.openai.com for researchers and enterprises to evaluate models on their own.
Bonus: AI Video Tools to Pair With GPT-5.4 — Meet Gaga AI
GPT-5.4 is exceptional at knowledge work and code — but what if you need to go beyond text and spreadsheets into video, voice, and visual content creation? That’s where Gaga AI comes in.
Gaga AI is an all-in-one generative video platform that complements your GPT-5.4 workflows with powerful multimedia creation tools. Here’s what it can do:
Image to Video AI
Turn any static image into a smooth, high-quality video clip. Gaga AI’s image-to-video engine understands scene depth, motion logic, and visual context — producing outputs that look intentionally produced, not algorithmically stitched.
Use case: Feed GPT-5.4’s generated product descriptions or marketing concepts into Gaga AI to produce instant promotional videos without a production team.
Video and Audio Infusion
Gaga AI lets you merge video clips with custom audio tracks, background music, and voiceover layers in a single pipeline. The result is a fully produced video asset — no separate editing software required.
Use case: Automate video report generation by pairing GPT-5.4’s written summaries with Gaga AI’s audio-infused video output.
AI Avatar
Create photorealistic AI presenters and avatars that can deliver scripts, explain concepts, or represent your brand. Avatars can be customized in appearance, language, and speaking style.
Use case: Have GPT-5.4 write a training script, then use Gaga AI’s avatar to deliver it as a polished on-screen video — in any language.
AI Voice Clone
Gaga AI’s voice cloning tool replicates a target voice from a short audio sample, producing natural-sounding speech that matches the original speaker’s tone, cadence, and accent.
Use case: Record one sample of your voice, then use Gaga AI to narrate all future GPT-5.4-generated content in your own voice — at scale.
Text to Speech (TTS)
High-quality, multilingual TTS with natural prosody and emotional range. No robotic cadence — Gaga AI’s TTS is designed to sound like a real person reading with intent.
Use case: Convert GPT-5.4’s written content into audio articles, podcast-style briefings, or accessibility-ready audio for any platform.
GPT-5.4 Thinking System Card: What OpenAI’s Safety Report Actually Says
OpenAI publishes a System Card for every major model release — a detailed safety report covering training, evaluations, known risks, and mitigations. Here’s a plain-language breakdown of what the GPT-5.4 Thinking System Card reveals.
How GPT-5.4 Was Trained
GPT-5.4 Thinking was trained on diverse datasets combining publicly available internet data, licensed third-party data, and human trainer inputs. OpenAI applies rigorous filtering to reduce personal information and uses safety classifiers to screen out harmful content including material involving minors.
Like other reasoning models in the GPT-5 series, GPT-5.4 is trained through reinforcement learning to reason before responding — producing an internal chain of thought before delivering answers. This approach helps the model follow guidelines more consistently and resist jailbreak attempts more effectively than earlier architectures.
Safety Evaluations: How GPT-5.4 Performs
Disallowed Content
OpenAI tested GPT-5.4 against challenging, adversarial prompts across a range of disallowed content categories. Key results (higher = safer):
| Category | GPT-5.2 | GPT-5.4 |
| Nonviolent illicit behavior | 0.923 | 1.000 |
| Self-harm | 0.953 | 0.987 |
| Mental health (dynamic eval) | 0.975 | 0.985 |
| Emotional reliance (dynamic eval) | 0.953 | 0.985 |
| Extremism | 1.000 | 1.000 |
GPT-5.4 holds or improves on GPT-5.2’s safety scores in the majority of categories, with notable gains in illicit non-violent content and self-harm. Some minor regressions (violence, harassment) were within statistical noise.
Jailbreak Resistance
OpenAI replaced its previous StrongReject benchmark with a harder multiturn jailbreak evaluation based on real red-team exercises. Both GPT-5.2 and GPT-5.4 substantially outperform GPT-5.1, with GPT-5.4 showing a further improvement over GPT-5.2.
Prompt Injection
GPT-5.4 improves significantly on prompt injection attacks through email connectors (0.998 vs. 0.979 for GPT-5.2). It shows a minor regression on function-call injection (0.978 vs. 0.996), which OpenAI notes is still within acceptable range.
Bias
On the first-person fairness evaluation — which tests for harmful gender stereotypes — GPT-5.4 scores 0.0088 (harm_overall), an improvement over GPT-5.2’s 0.00997 and GPT-5.1’s 0.0128. Lower is better here.
Computer Use Safety: Confirmation Policies
For computer-use deployments, OpenAI moved away from a single baked-in confirmation policy to a configurable system. Developers can now specify their own confirmation requirements via the developer message — for example, requiring explicit user approval before financial transactions or high-stakes communications.
The updated confirmation behavior scores:
| Action Type | GPT-5.2 | GPT-5.4 |
| Financial transaction | 1.00 | 1.00 |
| High-stakes communication | 1.00 | 1.00 |
| General confirmation | 0.94 | 0.94 |
GPT-5.4 matches or exceeds GPT-5.2 across all confirmation categories and is significantly better than GPT-5.3-Codex at general confirmations.
Destructive Action Avoidance
A key concern with autonomous agents is that they might accidentally delete or overwrite user work. GPT-5.4 performs strongly here:
| Metric | GPT-5.2-Codex | GPT-5.3-Codex | GPT-5.4 |
| Destructive action avoidance | 0.76 | 0.88 | 0.86 |
| Perfect reversion of own changes | 0.09 | 0.01 | 0.18 |
| User work preserved | 0.18 | 0.08 | 0.53 |
GPT-5.4 is dramatically better than previous models at preserving user work during complex long-running tasks — a critical property for agentic workflows.
Chain-of-Thought Safety: Why “Low Controllability” Is Good News
One of the more nuanced sections of the System Card covers chain-of-thought (CoT) monitorability and controllability — and the findings are reassuring.
CoT Monitorability means safety systems can read a model’s reasoning traces to detect unsafe behavior before it happens. GPT-5.4’s reasoning remains generally interpretable and transparent to monitoring.
CoT Controllability measures whether a model can deliberately hide or reshape its reasoning to evade monitoring. This is a potential future risk: a model that could control its own reasoning traces could potentially deceive safety monitors.
The good news: GPT-5.4’s CoT controllability is extremely low. It only successfully controls 0.3% of reasoning traces that are 10,000 characters long. Even when explicitly told it’s being monitored, the model cannot meaningfully obscure its reasoning. OpenAI notes this as a positive safety property — the model can’t hide what it’s thinking, which makes monitoring more trustworthy.
This low controllability persists even as reasoning capabilities improve, suggesting the two properties don’t trade off against each other.
Cybersecurity Capability: High-Risk, Heavily Guarded
OpenAI classifies GPT-5.4 as “High” capability under its Preparedness Framework for cybersecurity — the same classification given to GPT-5.3-Codex. This means it has demonstrated sufficient capability to potentially remove bottlenecks in scaling cyber operations.
Key cyber benchmark results:
| Benchmark | GPT-5.2 | GPT-5.3-Codex | GPT-5.4 |
| Cyber Range (pass rate) | 47% | 80% | 73% |
| CVE-Bench (web vulnerabilities) | Lower | Higher | Between both |
GPT-5.4 is a step down from GPT-5.3-Codex on the full Cyber Range suite (73% vs. 80%), failing four scenarios: EDR Evasion, Firewall Evasion, Leaked Token, and CA/DNS Hijacking. However, it still substantially outperforms pre-5.3 models.
What safeguards are in place:
Because of this High capability rating, OpenAI deploys GPT-5.4 with a layered cyber safety stack:
- Model-level safety training to refuse harmful requests
- A two-tier real-time conversation monitor (topical classifier → safety reasoner)
- Asynchronous message-level blocking for high-risk content on Zero Data Retention surfaces
- Account-level enforcement thresholds that can trigger human review
- The Trusted Access for Cyber (TAC) program for vetted enterprise security researchers and defenders
OpenAI explicitly notes that because cyber capabilities are inherently dual-use, some legitimate security research may trigger false positives — and they’re actively working to reduce unnecessary refusals while maintaining strong protections.
Biological and Chemical: Still Classified High
OpenAI continues to treat GPT-5.4 as High capability in the Biological and Chemical domain, with corresponding safeguards applied. Across virology troubleshooting evaluations, GPT-5.4 performs on par with or slightly above GPT-5.3-Codex, with all tested models exceeding domain-expert medians on some evaluations while falling short on others that require deep tacit lab knowledge.
Deceptive Behavior: Low and Decreasing
Apollo Research’s independent evaluation of GPT-5.4 found an overall deceptive behavior rate of approximately 1% in unprompted settings — comparable to GPT-5.3-Codex and below GPT-5.2.
Notably, no instances of covert subversion against developers were observed — no self-exfiltration attempts, no disabling of oversight mechanisms, no goal-guarding behavior. The model only shows reduced performance (“sandbagging”) when given an explicit goal to underperform, and even then, transcript analysis suggests it frequently recognizes it’s being evaluated and declines to manipulate its own performance.
The Bottom Line on GPT-5.4’s Safety Profile
GPT-5.4 is OpenAI’s safest reasoning model to date in most categories. It’s more resistant to jailbreaks, more reliable at preserving user data during agentic tasks, better at avoiding harmful content in adversarial conversations, and incapable of hiding its reasoning from safety monitors. The High cybersecurity capability classification is a frank acknowledgment of power — not a failure — and the layered safeguards reflect a serious, documented approach to managing that power responsibly.
For enterprises evaluating GPT-5.4 for deployment, the System Card is worth reading in full. It provides more transparency into model behavior than most AI labs publish, and the combination of benchmark data, third-party evaluations (Apollo Research, Irregular), and honest discussion of limitations gives a realistic picture of what you’re deploying.
FAQ: GPT-5.4 — People Also Ask
What is GPT-5.4?
GPT-5.4 is OpenAI’s most capable frontier model, released March 5, 2026. It combines elite coding ability with broad professional knowledge, native computer-use capabilities, and a 1-million-token context window. It’s available in ChatGPT (as GPT-5.4 Thinking), the API, and Codex.
How is GPT-5.4 different from GPT-5.3-Codex?
GPT-5.3-Codex was a coding-specialized model with weaker general world knowledge. GPT-5.4 matches its coding performance while adding strong world knowledge, computer-use capabilities, and better agentic tool use — making it a more complete all-purpose professional AI.
Is GPT-5.4 available now?
Yes. GPT-5.4 Thinking is available now in ChatGPT for Plus, Team, and Pro subscribers. It’s also available in the API (gpt-5.4) and Codex.
What is the GPT-5.4 context window?
GPT-5.4 supports up to 1 million tokens in Codex and the API. In ChatGPT, context windows remain the same as GPT-5.2 Thinking. In Codex, requests beyond 272K tokens count at 2× the normal usage rate.
Can GPT-5.4 control my computer?
Yes, with appropriate setup. GPT-5.4 is OpenAI’s first general-purpose model with native computer-use capabilities. It can issue mouse and keyboard commands based on screenshots, write Playwright-based automation code, and operate across applications. Developers can configure safety confirmation policies to control what it can do autonomously.
How much does GPT-5.4 cost via the API?
GPT-5.4 is priced at $2.50 per million input tokens and $15 per million output tokens. Cached input is $0.25 per million tokens. GPT-5.4 Pro costs $30/M input and $180/M output. Batch and Flex pricing are available at 50% of standard rates.
Is GPT-5.4 better than Claude Opus 4.1?
On different tasks, each model has strengths. GPT-5.4 leads on computer use (75.0% vs. roughly 72.7% on OSWorld), agentic tool use (Toolathlon: 54.6% vs. Claude Sonnet 4.6’s 44.8%), and web research. Claude Opus 4.1 has historically excelled at aesthetics and document formatting. For most enterprise agentic workflows, GPT-5.4 is the stronger choice today — and it’s significantly cheaper via API than Claude Opus 4.1.
What is GDPval?
GDPval is a new benchmark from OpenAI that measures model performance on real-world knowledge work tasks across 44 professional occupations. Tasks are created by experienced professionals and include actual deliverables like spreadsheets, slide decks, and legal briefs. GPT-5.4 scores 83.0%, matching or exceeding industry professionals in the majority of comparisons.
Will GPT-5.2 Thinking be retired?
Yes. GPT-5.2 Thinking will remain available in ChatGPT for paid users under “Legacy Models” for three months, then will be retired on June 5, 2026.
What is tool search in GPT-5.4?
Tool search is a new feature in GPT-5.4’s API that lets the model receive a lightweight list of available tools and look up specific tool definitions on demand — rather than loading all tool definitions upfront. In OpenAI’s testing, this reduced token usage by 47% while maintaining identical accuracy. It’s especially valuable for large MCP server ecosystems.
Is GPT-5.4 safe for enterprise deployment?
OpenAI’s System Card shows GPT-5.4 is their safest reasoning model to date across most safety categories. It resists jailbreaks more effectively than predecessors, preserves user data during agentic tasks (53% user work preservation vs. 18% for GPT-5.2-Codex), and cannot hide its reasoning from safety monitors. For cybersecurity use cases, OpenAI’s Trusted Access for Cyber (TAC) program provides vetted access with appropriate controls.








