
Key Takeaways
- Gemini 3.1 Flash-Lite launched March 4, 2026 — Google’s fastest, cheapest Gemini 3 model
- Output speed: 363 tokens/sec (5× faster than GPT-5 mini, 3.4× faster than Claude 4.5 Haiku)
- Price: $0.25/1M input tokens, $1.50/1M output tokens — 4× cheaper than Claude 4.5 Haiku
- Benchmark wins: 86.9% GPQA Diamond, 76.8% MMMU Pro, 88.9% MMMLU
- Supports text, image, audio, and video inputs with 1M token context window
- Available now via Gemini API (Google AI Studio) and Vertex AI
Table of Contents
What Is Gemini 3.1 Flash‑Lite?
Gemini 3.1 Flash-Lite is Google’s fastest and most cost-efficient model in the Gemini 3 series, designed specifically for high-volume, latency-sensitive developer workloads.
Launched on March 4, 2026, it breaks the traditional trade-off between price and performance. It’s built on the same foundation as Gemini 3 Pro, then distilled into a lightweight form — so you get near-flagship intelligence at a fraction of the cost.
Google CEO Sundar Pichai called it “the fastest and most cost-effective model in the Gemini 3 series,” while Google AI Studio product lead Logan Kilpatrick described it as “a major step forward at the intelligence frontier.”
How Fast Is Gemini 3.1 Flash‑Lite? (Speed Breakdown)
Speed is Flash-Lite’s most disruptive advantage. At 363 tokens per second, it’s in a category of its own among cloud-hosted models.
| Model | Output Speed (tokens/s) | Input Price ($/1M tokens) | Output Price ($/1M tokens) |
| Gemini 3.1 Flash-Lite | 363 | $0.25 | $1.50 |
| Gemini 2.5 Flash | 249 | $0.30 | $2.50 |
| Gemini 2.5 Flash-Lite | 366 | $0.10 | $0.40 |
| GPT-5 mini | 71 | $0.25 | $2.00 |
| Claude 4.5 Haiku | 108 | $1.00 | $5.00 |
| Grok 4.1 Fast | 145 | $0.20 | $0.50 |
To put this in real terms: Flash-Lite processes the same workload in the time it takes GPT-5 mini to get started. Translating a 1,000-word technical document happens in under one second.
Compared to the previous generation, Flash-Lite is 45% faster than Gemini 2.5 Flash and delivers a 2.5× improvement in Time to First Answer Token — meaning your users feel the difference immediately.
Is Gemini 3.1 Flash‑Lite Actually Cheaper?
Yes — dramatically. At $0.25/1M input tokens and $1.50/1M output tokens, Flash-Lite undercuts Claude 4.5 Haiku by 4× on input and more than 3× on output.
Here’s a real cost calculation for a mid-size e-commerce platform processing 10 million tokens per day:
- Flash-Lite: ~$17.50/day ($6,388/year)
- Claude 4.5 Haiku: ~$60/day ($21,900/year)
- GPT-5 mini: ~$22.50/day ($8,213/year)
That’s a $15,000+ annual saving switching from Claude 4.5 Haiku to Flash-Lite for the same workload. For enterprise-scale operations processing billions of tokens, the gap runs into millions of dollars.
Flash-Lite is also 8× cheaper than Gemini 3.1 Pro — making it the obvious choice for any task that doesn’t need top-tier reasoning.
Gemini 3.1 Flash‑Lite Benchmarks: How Does It Score?
Flash-Lite doesn’t just win on speed and price — it punches far above its weight class on intelligence benchmarks.
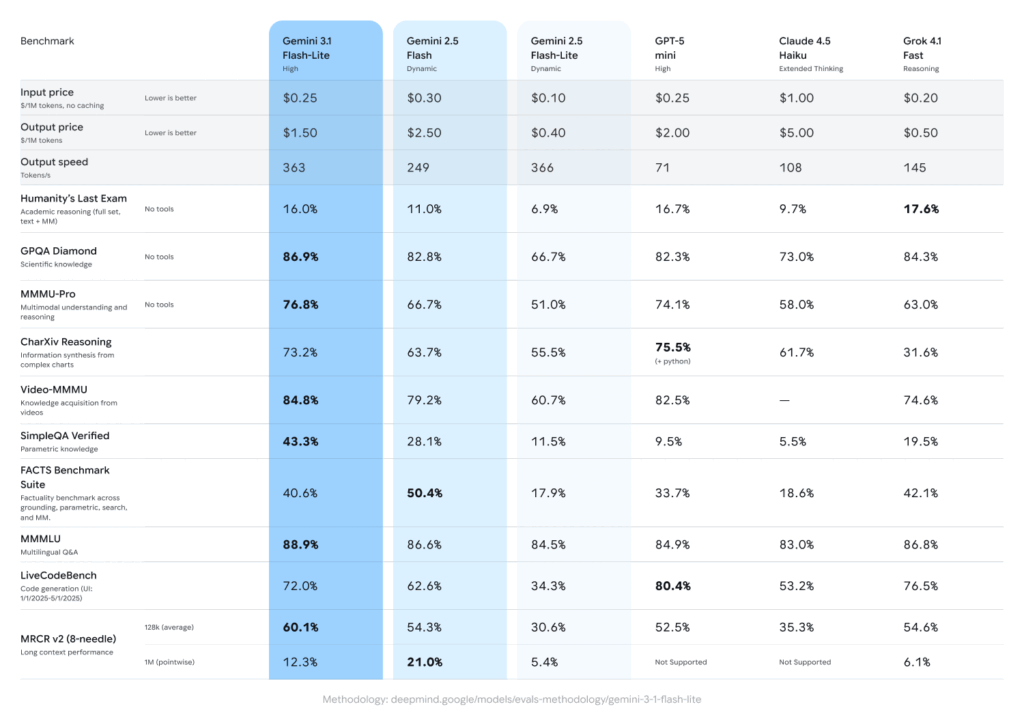
Scientific Reasoning — GPQA Diamond
Flash-Lite scores 86.9%, beating:
- GPT-5 mini (82.3%)
- Claude 4.5 Haiku (73.0%)
- Gemini 2.5 Flash (82.8%)
GPQA Diamond is a PhD-level test covering physics, chemistry, biology, and mathematics. Scoring nearly 87% as a lightweight model is genuinely remarkable.
Multimodal Understanding — MMMU Pro
Flash-Lite scores 76.8%, beating:
- GPT-5 mini (74.1%)
- Gemini 2.5 Flash (66.7%)
- Grok 4.1 Fast (63.0%)
- Claude 4.5 Haiku (58.0%)
MMMU Pro tests understanding across text, images, and tables with cross-modal reasoning required. Upload a financial report as an image and ask for trend analysis — Flash-Lite extracts data, identifies anomalies, and delivers structured insights.
Factual Accuracy — SimpleQA Verified
Flash-Lite scores 43.3%, far ahead of:
- Gemini 2.5 Flash (28.1%)
- Grok 4.1 Fast (19.5%)
- GPT-5 mini (9.5%)
- Claude 4.5 Haiku (5.5%)
This isn’t a minor gap — Flash-Lite is roughly 8× more factually accurate than Claude 4.5 Haiku on this test.
Multilingual — MMMLU
Flash-Lite scores 88.9%, top of its tier, beating Gemini 2.5 Flash (86.6%) and GPT-5 mini (84.9%). It supports dozens of languages including English, French, German, Japanese, Korean, and many others.
Video Understanding — Video-MMMU
Flash-Lite scores 84.8% — highest in its class, ahead of GPT-5 mini (82.5%) and Gemini 2.5 Flash (79.2%).
Where Flash-Lite Falls Short
Honestly: code generation. On LiveCodeBench, Flash-Lite scores 72.0% vs. GPT-5 mini’s 80.4% and Grok 4.1 Fast’s 76.5%. For complex programming tasks, you may want to route those to a stronger model.
On Humanity’s Last Exam (advanced academic reasoning), it scores 16.0% — essentially tied with GPT-5 mini (16.7%) and slightly behind Grok 4.1 Fast (17.6%).
What Can Gemini 3.1 Flash‑Lite Actually Do?
Real-Time Responses at Scale
Flash-Lite’s 363 tokens/sec makes it ideal for customer-facing applications where latency kills experience. Chatbots, live Q&A, instant search summaries — users get answers before they register a delay.
Multimodal Document Processing
Upload PDFs, images, audio, or video and ask Flash-Lite to extract, classify, or summarize. A 50-page academic PDF converts to clean Markdown (formulas, citations, tables intact) in about 20 seconds. Processing 10,000 product images for classification and tagging takes around 10 minutes — work that would take a team of three people three days.
Dynamic Dashboards and Data Visualization
Flash-Lite can generate real-time data dashboards by combining live API data with its analytical capabilities. Ask for a 7-day weather forecast dashboard for any city and you’ll get temperature trends, precipitation probability, air quality — rendered with chart recommendations — in one prompt.
SaaS Agent Workflows
Flash-Lite is purpose-built for multi-step automated pipelines. Order tracking, inventory alerts, customer ticket routing, sales report generation — all tasks that run thousands of times a day at costs that don’t break the budget.
Content Moderation and Classification
High-frequency content moderation — flagging spam, sorting user-generated content, labeling product categories — runs efficiently at Minimal thinking mode, keeping speed and cost at rock bottom.
The “Thinking Levels” Feature: What Is It and Why It Matters
Thinking Levels is one of Flash-Lite’s most practical and underrated features. It lets developers dial in exactly how much the model “thinks” before responding — giving direct control over the speed/quality/cost triangle.
There are four levels:
- Minimal — Maximum speed, minimum cost. Best for translation, classification, content moderation. Example: 10,000 words translated in 5 seconds for $0.015.
- Low — Slightly more deliberate. Good for summarization, extraction, light Q&A.
- Medium — Balanced reasoning. Works for customer support, structured data generation.
- High — Full deliberation. Generates UI layouts, complex instructions, multi-step plans. Results match mid-tier models on most tasks.
You can even use Flash-Lite as a model router: let it assess incoming task complexity, handle simple queries itself, and forward complex ones to Gemini 3.1 Pro. The result — fast responses for the majority of users, with high-quality handling for edge cases, at a blended cost far below using Pro for everything.
How to Access Gemini 3.1 Flash‑Lite
Flash-Lite is available now in preview through two channels:
For Developers — Google AI Studio
- Go to aistudio.google.com
- Create or sign into your Google account
- Select model ID: gemini-3.1-flash-lite-preview
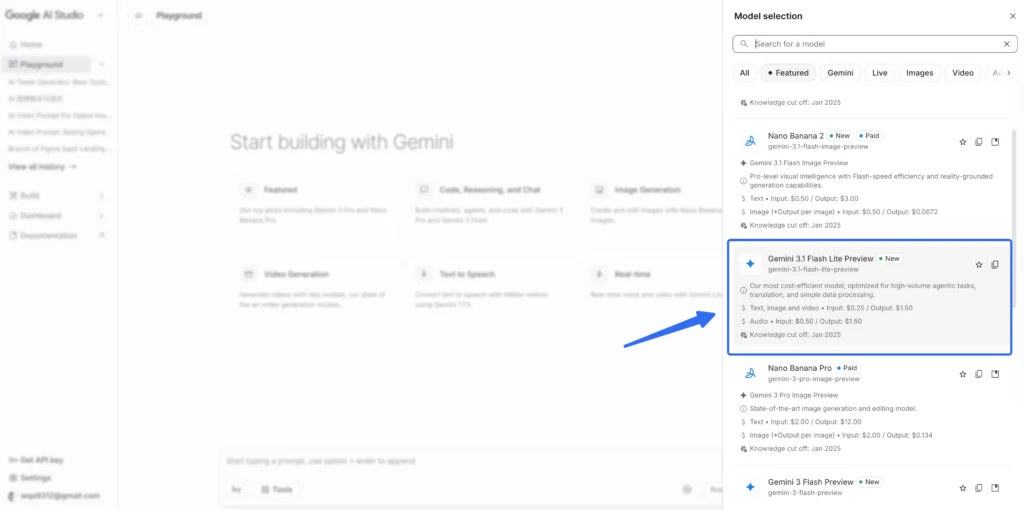
- Free tier available — no credit card required to start
- Supports text, image, audio, and video inputs
- Up to 1M token context window; 64K token output
For Enterprises — Vertex AI
- Go to cloud.google.com/vertex-ai
- Enable the Vertex AI API in your Google Cloud project
- Use model ID: gemini-3.1-flash-lite-preview
- Enterprise SLAs, compliance controls, and private endpoints available
Note: Flash-Lite is not yet available in the Gemini consumer app — API access only. Knowledge cutoff date is January 2025.
Gemini 3.1 Flash‑Lite vs. Competitors: The Honest Verdict
Flash-Lite wins on:
- Speed — No cloud model at this price point comes close
- Multimodal understanding — Tops its tier on MMMU Pro and Video-MMMU
- Factual accuracy — The SimpleQA gap vs. competitors is staggering
- Multilingual performance — Best-in-class at MMMLU
Flash-Lite loses on:
- Complex code generation — GPT-5 mini leads here
- Advanced academic reasoning — Grok 4.1 Fast edges it out on Humanity’s Last Exam
- Very long context at scale — 1M token pointwise performance (12.3%) lags behind Gemini 2.5 Flash (21.0%)
Bottom line: For the vast majority of high-volume production use cases — classification, translation, moderation, multimodal analysis, agent pipelines — Gemini 3.1 Flash-Lite is the best value in the market right now.
What Gemini 3.1 Flash‑Lite Means for the AI Industry
Flash-Lite shifts the competitive axis in AI from “who’s smartest” to “who’s most useful per dollar.”
Before Flash-Lite, enterprise AI adoption was gated by cost. Running millions of AI calls per day was a luxury. Flash-Lite makes it routine. At $0.25/1M input tokens, any startup or mid-size business can afford production-scale AI workloads.
This will force OpenAI, Anthropic, and others to respond — either by cutting prices, releasing lighter models, or improving their own efficiency. For developers and businesses, that’s unambiguously good news.
Google’s product strategy is now clear: Pro for peak performance, Flash for everyday scale, Flash-Lite for cost-optimized volume. It’s the same playbook as flagship/mid-range/budget in consumer hardware — and it’s how you win an entire market, not just a benchmark leaderboard.
BONUS: Pair Flash‑Lite with Gaga AI for End-to-End Video Creation
Processing content at scale is only half the equation. If you’re building AI-powered media workflows, Gaga AI closes the loop by turning text and images into polished video content — no production team required.
Here’s what Gaga AI brings to your stack:
Image-to-Video Generation
Feed Gaga AI a static image — a product shot, a concept illustration, a character render — and watch it become a fluid, cinematic video clip. Combine with Flash-Lite’s image analysis to auto-generate video briefs from visual assets at scale.
Video + Audio Infusion
Gaga AI doesn’t just generate visuals — it syncs background music, sound effects, and ambient audio to match the mood and pacing of your video. No manual audio editing. No licensing headaches.
AI Avatar Generation
Create hyper-realistic AI presenters that speak directly to camera. Ideal for explainer videos, product demos, e-learning content, and social media — without booking a studio or a human host.
AI Voice Cloning
Clone any voice — yours, a brand persona, a celebrity-style character — and use it across unlimited video content. Consistency across thousands of assets, at zero incremental recording cost.
Text-to-Speech (TTS)
Need fast narration for a batch of product videos? Gaga AI’s TTS converts your script into natural-sounding speech in seconds, with tone and pace control baked in.
The workflow: Use Gemini 3.1 Flash-Lite to analyze, classify, and generate scripts from your raw content. Pass those scripts and assets to Gaga AI to render final video output — with voice, music, and avatar delivery. You’ve just built a fully automated video production pipeline.
Frequently Asked Questions
What is Gemini 3.1 Flash-Lite?
Gemini 3.1 Flash-Lite is Google’s fastest and most affordable model in the Gemini 3 series, launched March 4, 2026. It’s designed for high-volume AI workloads that need low latency and low cost, including translation, content classification, multimodal analysis, and agentic pipelines.
How fast is Gemini 3.1 Flash-Lite?
It outputs 363 tokens per second — about 5× faster than GPT-5 mini (71 tokens/sec) and 3.4× faster than Claude 4.5 Haiku (108 tokens/sec). Time to First Answer Token is 2.5× faster than Gemini 2.5 Flash.
How much does Gemini 3.1 Flash-Lite cost?
Input is $0.25 per million tokens. Output is $1.50 per million tokens. There’s no caching surcharge at these base rates. It’s approximately 4× cheaper than Claude 4.5 Haiku on input and 8× cheaper than Gemini 3.1 Pro.
Is Gemini 3.1 Flash-Lite better than GPT-5 mini?
On most benchmarks, yes. Flash-Lite leads on scientific reasoning (GPQA Diamond: 86.9% vs. 82.3%), multimodal understanding (MMMU Pro: 76.8% vs. 74.1%), factual accuracy (SimpleQA: 43.3% vs. 9.5%), multilingual (MMMLU: 88.9% vs. 84.9%), and video understanding. GPT-5 mini leads on code generation (80.4% vs. 72.0%).
Can Gemini 3.1 Flash-Lite handle images, video, and audio?
Yes. Flash-Lite is natively multimodal. It accepts text, images, audio files, and video as inputs, with a 1M token context window. Output is text-only (up to 64K tokens).
How do I access Gemini 3.1 Flash-Lite?
Via Google AI Studio (aistudio.google.com) using model ID gemini-3.1-flash-lite-preview, or via Vertex AI for enterprise use. A free tier is available in AI Studio. It is not yet available in the Gemini consumer app.
What is the “thinking levels” feature?
Thinking levels lets developers set how deeply the model reasons before responding — from Minimal (fastest, cheapest, great for classification) to High (more deliberate, ideal for generating UIs or following complex instructions). It’s available in both AI Studio and Vertex AI.
What are the best use cases for Gemini 3.1 Flash-Lite?
High-frequency, cost-sensitive workloads: customer service automation, e-commerce content generation, content moderation, multilingual processing, document-to-Markdown conversion, real-time dashboards, and multi-step AI agent workflows.
What is Gemini 3.1 Flash-Lite’s knowledge cutoff?
January 2025.
Is Gemini 3.1 Flash-Lite safe to use in production?
Yes. It outperforms Gemini 2.5 Flash-Lite on tone evaluation (+14.59%) and reduces unjustified refusals (-14.41%), while maintaining strong safety policies. Google conducted both automated safety evaluations and human red teaming before launch.





