Key Takeaways
- Hunyuan-GameCraft-2 is a generative world model that creates controllable, interactive game videos from natural language instructions combined with keyboard/mouse signals
- Achieves real-time performance at 16 FPS through FP8 quantization, parallelized VAE decoding, and optimized attention mechanisms
- Built on a 14B Mixture-of-Experts (MoE) foundation using autoregressive distillation and randomized long-video tuning to maintain temporal coherence
- Introduces InterBench evaluation protocol measuring six dimensions of interaction quality: trigger rate, alignment, fluency, scope, end-state consistency, and physics correctness
- Supports three interaction categories: environmental changes (weather, explosions), actor actions (drawing weapons, opening doors), and entity appearances (vehicles, animals)
- Generalizes beyond training data by learning underlying interaction structures rather than memorizing visual patterns
Table of Contents
What Is Hunyuan-GameCraft-2?
Hunyuan-GameCraft-2 is an instruction-driven interactive game world model developed by Tencent Hunyuan that advances generative video from static scene synthesis to open-ended, instruction-following interactive simulation. Unlike traditional video generation models that produce predetermined sequences, this system dynamically responds to user inputs in real-time, creating explorable and playable game environments.
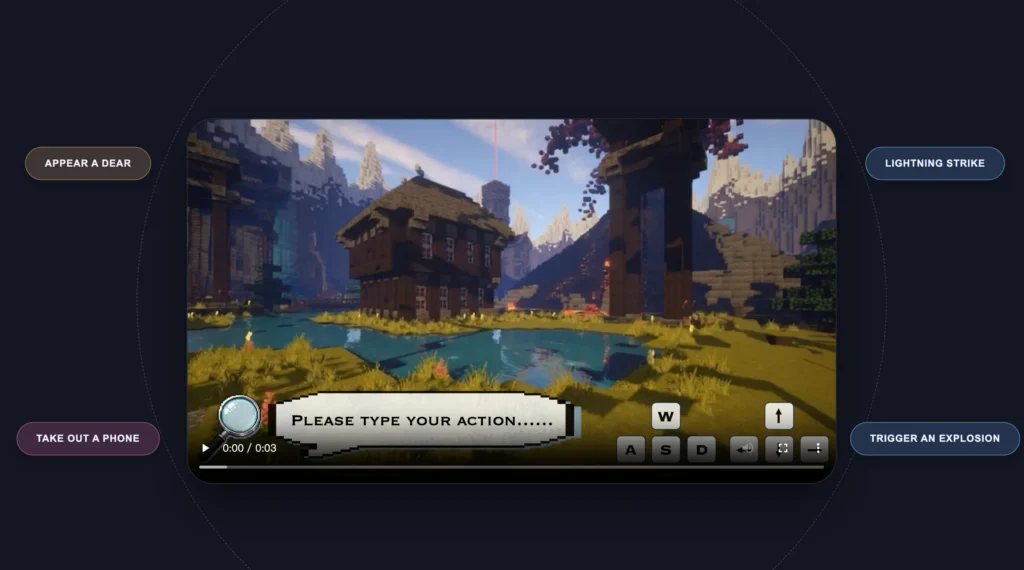
The model processes three types of control signals simultaneously:
- Natural language prompts (“draw a torch”, “trigger an explosion”)
- Keyboard inputs (W/A/S/D for movement)
- Mouse actions (directional changes, interactions)
The model builds upon a 14B image-to-video Mixture-of-Experts foundation and incorporates a text-driven interaction injection mechanism for fine-grained control over camera motion, character behavior, and environment dynamics.
Why Hunyuan-GameCraft-2 Matters: The Shift to Interactive World Models
The Problem with Static Video Generation
Existing world models remain limited by rigid action schemas and high annotation costs, restricting their ability to model diverse in-game interactions and player-driven dynamics. Previous approaches fell into two camps:
3D-Based Models:
- Emphasize geometric consistency and physical accuracy
- Limited to scripted or static interactions
- Lack creative flexibility for open-ended gameplay
Video-Based Models:
- Learn world dynamics from large-scale video data
- Struggle with long-term consistency
- Constrained by discrete input devices (keyboard/mouse only)
The Interactive Data Bottleneck
Current video data suitable for training interactive world models remain scarce, as real-world captured videos are costly and time-consuming to collect, simulation-based generation provides strong controllability but restricts scene diversity, and internet videos have highly inconsistent quality.
How Hunyuan-GameCraft-2 Works: Technical Architecture
1. Interactive Video Data Construction
Interactive Video Data is defined as a temporal sequence that explicitly records a causally driven state-transition process, where agents or the environment transition from a clearly defined initial state to a significantly different final state through significant state transitions, subject emergence or interaction, and scene shifts or evolution.
Synthetic Data Pipeline:
The system employs two strategies for generating training data:
Start-End Frame Strategy (for stationary scenes):
- Vision-Language Model (VLM) analyzes initial frame
- Image editing model generates target end-frame
- Provides strong controllability over final state
- Used for environmental changes like “making it snow”
First-Frame-Driven Strategy (for dynamic actions):
- Generates freely from only the initial frame
- Avoids distortions in camera movement
- Yields smoother temporal continuity
- Used for actions like “opening a door”
2. Game Scene Data Curation
The dataset is built from over 150 AAA games (e.g., Assassin’s Creed, Cyberpunk 2077), providing extensive diversity in environments, lighting, artistic styles, and camera viewpoints.
Four-Stage Processing Pipeline:
1. Scene and Action-aware Partition: Uses PySceneDetect for visual coherence and RAFT optical flow for action boundaries
2. Quality Filtering: Learning-based artifact removal, luminance checks, and VLM semantic verification
3. Camera Annotation: Reconstructs 6-DoF camera trajectories using VIPE for each clip
4. Structured Captioning: Generates standard captions (visual content) and interaction captions (state transitions)
3. Model Architecture Components
Multimodal Input Integration:
The model integrates text-based instructions and keyboard/mouse action signals into a unified controllable video generator, with keyboard and mouse signals mapped to continuous camera control parameters encoded as Plücker embeddings and integrated through token addition.
Key Technical Features:
- Mixture-of-Experts (MoE) Design: Separates high-noise and low-noise expert pathways for efficient processing
- Causal DiT Blocks: Enable autoregressive generation while maintaining temporal consistency
- 3D VAE Encoder: Compresses video into latent space for efficient processing
- MLLM Enhancement: Extracts and injects interaction information for fine-grained control
4. Training Strategy (Four Stages)
Stage 1: Action-Injected Training
- Establishes understanding of 3D scene dynamics, lighting, and physics
- Curriculum learning: 45 → 81 → 149 frames at 480p resolution
- Adapts attention mechanisms for long-duration coherence
Stage 2: Instruction-Oriented Supervised Fine-Tuning
- 150K samples combining real gameplay and synthetic videos
- Freezes camera encoder parameters
- Fine-tunes MoE experts for semantic control alignment
Stage 3: Autoregressive Generator Distillation
- Converts bidirectional model to causal autoregressive generation
- Implements sink token mechanism to prevent quality drift
- Uses Block Sparse Attention for local temporal context
Stage 4: Randomized Long-Video Extension Tuning
- Uses a dataset of long-form gameplay videos exceeding 10 seconds with randomized extension tuning where the model autoregressively rolls out N frames, and contiguous T-frame windows are uniformly sampled to align predicted and target distributions.
- Interleaves self-forcing with teacher-forcing to maintain interactive capabilities
- Mitigates error accumulation during extended rollouts
How to Use Hunyuan-GameCraft-2: Practical Implementation
Multi-Turn Interactive Inference
KV Cache Management:
The inference process employs a fixed-length self-attention KV cache with a rolling update mechanism where sink tokens are permanently retained at the beginning of the cache window, and the subsequent segment functions as a local attention window maintaining the N frames preceding the target denoising block.
ReCache Mechanism:
- Upon receiving new interaction prompt, model extracts interaction embeddings
- Recomputes last autoregressive block
- Updates both self-attention and cross-attention KV caches
- Provides precise historical context with minimal computational overhead
Performance Optimization Techniques
The system achieves 16 FPS through FP8 quantization to reduce memory bandwidth, parallelized VAE decoding for simultaneous latent-frame reconstruction, SageAttention to replace FlashAttention with optimized quantized attention kernel, and sequence parallelism distributing video tokens across multiple GPUs.
Resolution and Frame Configuration:
- Standard resolution: 832×448 pixels
- Default length: 93 frames per generation
- Supports autoregressive extension up to 500+ frames
- Context parallelism for distributed processing
Evaluating Interactive Performance: The InterBench Protocol
What InterBench Measures
InterBench is a six-dimensional evaluation protocol that measures not only whether an interaction is triggered, but also its fidelity, smoothness, and physical plausibility over time.
Six Core Dimensions:
1. Interaction Trigger Rate (Binary)
- Whether requested interaction was successfully initiated
- Gateway check separating ignored prompts from attempted actions
2. Prompt–Video Alignment (1-5 Scale)
- Static alignment: maintaining scene context and objects
- Dynamic alignment: executing correct action as specified
3. Interaction Fluency (1-5 Scale)
- Temporal naturalness and visual coherence
- Penalizes jumps, flickering, object teleportation
4. Interaction Scope Accuracy (1-5 Scale)
- Whether spatial extent of effects is appropriate
- Global events affect entire scene; local actions have contained influence
5. End-State Consistency (1-5 Scale)
- Whether interaction converges to stable final state
- Distinguishes completed actions from partial executions
6. Object Physics Correctness (1-5 Scale)
- Structural integrity of rigid bodies
- Realistic motion kinematics
- Correct contact relationships
Overall Score Calculation:
Overall = (5 × Trigger + Align + Fluency + Scope + EndState + Physics) / 6
Performance Benchmarks
Comparison Against State-of-the-Art Models:
| Category | Model | Trigger | Overall Score |
| Environmental | GameCraft-2 | 0.962 | 4.426 |
| Environmental | LongCat-Video | 0.897 | 4.000 |
| Environmental | Wan2.2 | 0.799 | 3.628 |
| Environmental | HunyuanVideo | 0.490 | 2.064 |
| Actor Actions | GameCraft-2 | 0.983 | 4.380 |
| Actor Actions | Wan2.2 | 0.836 | 3.737 |
| Entities | GameCraft-2 | 0.944 | 4.249 |
| Entities | Wan2.2 | 0.874 | 3.910 |
GameCraft-2 achieves Trigger scores of 0.962 for Environmental Interactions and a near-perfect 0.983 for Actor Actions, far surpassing all baselines, and outperforms the next-best model by margins of 0.683 in Physics for Environmental Interactions and over 0.52 in Entity & Object Appearances.
Three Categories of Supported Interactions
1. Environmental Interactions
Simple Effects:
- Weather changes: Snow, rain, lightning
- Global scene coverage with dynamic accumulation
- Realistic lighting interactions
Complex Events:
- Explosions: Fire, smoke, debris with proper physics
- Environmental state transitions with causal consistency
Technical Achievement: The model’s generated environmental effects achieve global coverage and dynamic accumulation, rendering them more physically plausible than baseline approaches.
2. Actor Actions
Primitive Actions:
- Draw gun, draw knife, take out torch
- Stable object grasping and manipulation
- Correct hand-object contact relationships
Composite Actions:
- Draw and fire gun (multi-step sequences)
- Take out and operate phone
- Open door with proper door-character interaction
Generalization Capability: The model successfully handles previously unseen actions like “taking out a phone” despite no training examples, demonstrating learned transferable interaction principles.
3. Entity and Object Appearances
Animals:
- Cat, dog, wolf, deer (basic)
- Dragon (extended complexity)
Vehicles:
- Red SUV, blue truck, yellow sports car, black off-road car
- Proper scene integration with lighting and perspective
Humans:
- Character appearance and emergence
- Identity consistency throughout sequence
Limitations and Current Constraints
1. Long-Term Coherence Challenges
While the randomized long-video tuning strategy alleviates error accumulation in autoregressive generation, it does not entirely eliminate it, and semantic drift may still manifest in long sequences exceeding 500 frames.
Root Cause: Lack of explicit long-term memory mechanism; model relies on finite KV cache capacity.
2. Interaction Scope Limitations
Currently Supported:
- Single-step, immediate-effect actions
- Direct cause-and-effect relationships
Not Yet Supported:
- Multi-stage tasks requiring logical reasoning
- Complex planning across multiple interaction steps
- Conditional behaviors based on prior state
3. Hardware and Deployment Constraints
Current Performance:
- Real-time at 16 FPS on high-end GPUs
- Requires optimization for accessible hardware
- Latency needs reduction for highly reactive gameplay
Resolution Trade-offs:
- Currently operates at 480p (832×448)
- Higher resolutions would impact frame rate
- Balance between quality and real-time performance
Comparison: Hunyuan-GameCraft-2 vs. Competing World Models
| Feature | GameCraft-2 | Genie 3 | Matrix-Game | GameGen-X |
| Resolution | 480p | 720p | 720p | 720p |
| Action Type | Key+Mouse+Prompt | Key+Mouse | Key+Mouse | Key+Mouse |
| Action Space | Continuous & Open-ended | Unknown | Discrete | Discrete |
| Generalizable | ✔ | ✔ | ✔ | ✔ |
| Scene Memory | ✔ | ✔ | ✗ | ✔ |
| Real-time | ✔ (16 FPS) | ✔ | ✗ | ✗ |
| Training Data | Gameplay + Rendered + Interaction | Unknown | Gameplay + Rendered | Gameplay |
Key Differentiator: GameCraft-2 is the only model integrating key/mouse signals with prompt-based instruction in a continuous, open-ended action space while maintaining real-time performance and scene memory.
Gaga AI: Character-Focused Video Generation for Games
While Hunyuan-GameCraft-2 focuses on interactive world modeling and environmental simulation, Gaga AI takes a complementary approach by specializing in character-driven video generation. Developed by Sand.ai, Gaga AI employs the GAGA-1 model, which creates video and audio simultaneously to produce complete digital performances rather than stitching together separate elements.
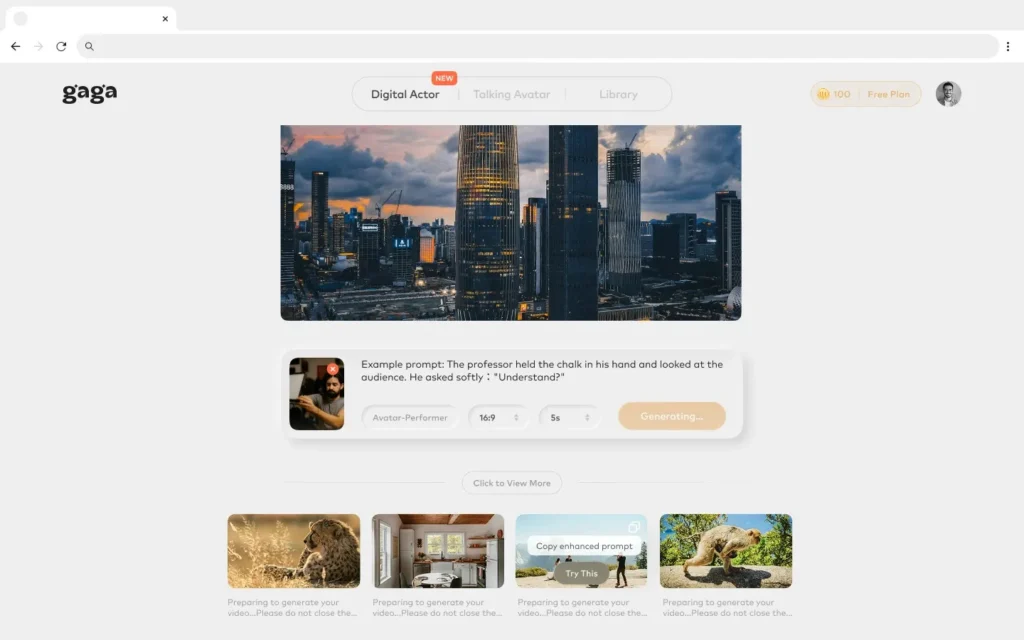
Core Capabilities for Game Content Creation
Gaga AI excels at creating animated character content with 5-10 second motion clips that can serve as reference material for game cinematics and promotional content. The platform addresses a critical gap in game development workflows by focusing on emotional authenticity and natural character movement.
Key Features
Holistic Performance Generation
Voice, lip-sync, and facial expressions are co-generated in one unified performance, creating seamless and emotionally convincing results.
Character Realism
Characters display genuine emotions and natural gestures, with tested prompts showing accurate facial expressions like frowning and slouched shoulders for disappointment.
Multi-Language Support
Compatible with English, Chinese, and Spanish dialogue with synchronized lip movements.
Rapid Generation
10-second videos render in approximately 3-4 minutes at 720p resolution.
Practical Applications in Game Development
Game developers can leverage Gaga AI across multiple production stages:
Pre-Production and Concept Development
- Generate animated character concepts for pitch presentations
- Create reference footage for character movement and emotional expressions
- Prototype dialogue scenes before committing to full production
Marketing and Promotional Content
- Produce character introduction videos for social media
- Generate trailer sequences featuring game characters
- Create promotional clips for TikTok, Instagram Reels, and YouTube Shorts
Educational and Training Materials
- Develop tutorial videos with in-game character guides
- Create onboarding sequences with animated instructors
- Build interactive learning experiences with virtual tutors
Workflow Integration
The typical Gaga AI workflow for game character videos:
1. Image Creation
Upload a character portrait (JPG/PNG) at 1080×1920px (vertical) or 1920×1080px (horizontal), or generate one using the built-in image creation tool.
2. Script Input
Provide text dialogue or upload audio recordings that define character speech and actions.
3. Rendering
The AI automatically synchronizes voice with motion, expressions, and hand gestures.
4. Output
Receive 720p video clips suitable for direct use or further refinement in professional editing tools.
Future Directions and Research Opportunities
1. Explicit Memory Systems
Need: Replace KV cache with dedicated long-term memory architecture Benefit: Eliminate semantic drift in ultra-long sequences (1000+ frames) Approach: Integrate memory banks similar to WorldMem framework
2. Multi-Stage Task Planning
Goal: Enable logical reasoning across interaction sequences Example: “Find a key, unlock the door, enter the room” Challenge: Requires state tracking and conditional execution
3. Hardware Accessibility
Optimization Targets:
- Reduce latency below 60ms for responsive gameplay
- Enable deployment on consumer-grade GPUs
- Mobile device compatibility through model compression
4. Resolution Scaling
Current Limitation: 480p balances quality and speed Target: 1080p while maintaining 16+ FPS Approach: Hierarchical generation with progressive refinement
Frequently Asked Questions (FAQ)
What makes Hunyuan-GameCraft-2 different from traditional video generators?
Hunyuan-GameCraft-2 generates interactive videos that respond dynamically to user inputs in real-time, rather than producing predetermined sequences. It unifies natural language prompts with keyboard/mouse controls, enabling semantic interaction (“draw a gun”) alongside spatial navigation. Traditional models generate static videos from text descriptions without causal user control.
How does the model maintain consistency in long video sequences?
The system employs three mechanisms: (1) a sink token that permanently retains the initial frame as a reference point, (2) block sparse attention maintaining local temporal context across recent frames, and (3) randomized long-video tuning that exposes the model to error accumulation during training. The KV cache rolling update mechanism prevents quality drift while enabling sequences exceeding 450 frames.
Can Hunyuan-GameCraft-2 handle interactions not present in training data?
Yes. The model demonstrates strong generalization capabilities by learning underlying interaction structures rather than memorizing visual patterns, successfully handling previously unseen subjects like “a dragon emerging” or actions like “taking out a phone” despite their absence from training data. It extrapolates learned principles of object emergence and action-driven causality to novel scenarios.
What hardware is required to run Hunyuan-GameCraft-2 in real-time?
Real-time 16 FPS performance requires high-end GPUs with FP8 quantization support and sufficient VRAM for the 14B parameter MoE model. The system uses parallelized VAE decoding and sequence parallelism across multiple GPUs for optimal performance. Consumer-grade deployment remains a limitation requiring further optimization.
How does InterBench differ from standard video quality metrics?
Standard metrics (FVD, temporal consistency, aesthetic score) measure visual fidelity and coherence but fail to capture interaction-specific properties. InterBench evaluates six dimensions unique to interactive video: whether actions trigger successfully, alignment with semantic intent, motion fluency, spatial effect scope, end-state stability, and physical plausibility. It provides action-level assessment rather than frame-level quality measurement.
What types of games or scenarios work best with this model?
The model excels in third-person perspective games with continuous camera motion, environmental effects, and object interactions. Optimal scenarios include open-world exploration, action sequences with weapon handling, and dynamic weather systems. It currently struggles with ultra-complex multi-agent scenarios, extended sequences beyond 500 frames, and tasks requiring multi-step logical planning.
How is camera control integrated with text-based interaction?
Keyboard and mouse signals are mapped to continuous camera control parameters encoded as Plücker embeddings and integrated into the model through token addition, while text prompts control semantic content like “trigger an explosion” through a multimodal large language model that extracts interaction-specific information. These signals operate in a unified controllable generation framework.
What is the synthetic data pipeline and why is it necessary?
The synthetic interaction video pipeline addresses the scarcity of interactive training data by leveraging vision-language models to analyze initial frames and generate scene-specific prompts, then applies either start-end frame strategy for stationary scenes or first-frame-driven strategy for dynamic actions. This automated production enables large-scale dataset creation without manual annotation costs.
Can the model generate videos longer than the training length?
Yes, through autoregressive generation. The model is trained on clips up to 149 frames but can extend sequences beyond 450 frames using the sink token mechanism and randomized long-video tuning. However, semantic drift may still manifest in sequences exceeding 500 frames due to the lack of explicit long-term memory and reliance on finite KV cache capacity.
What are the primary failure modes observed in testing?
Common failure patterns include: (1) interaction trigger failure when prompts are ambiguous or outside training distribution, (2) physics violations in hand-object contact for complex manipulation, (3) identity drift for newly appeared entities in extended sequences, (4) temporal artifacts like flickering when scene complexity exceeds model capacity, and (5) error accumulation in ultra-long generations beyond 500 frames.








