The AI video generation landscape is experiencing a seismic shift. Every few months, a new breakthrough emerges that redefines what’s possible in automated content creation. Enter Waver 1.0, ByteDance’s latest innovation that’s sending ripples through the creative technology world. This isn’t just another incremental update—it’s a fundamental reimagining of how waver ai video generator technology should work.

While competitors have been racing to improve individual capabilities, ByteDance took a different approach with Waver 1.0: unification. Instead of building separate models for different tasks, they’ve created a single, elegant framework that handles text-to-video, image-to-video, and text-to-image generation simultaneously. The result? A model that ranks in the Top 3 on industry leaderboards while delivering 1080p videos with unprecedented motion quality and stylistic range.
In this comprehensive analysis, we’ll explore everything that makes Waver 1.0 special—from its innovative rectified flow architecture to its practical creative capabilities—and examine what this breakthrough means for the future of AI-powered video creation.
Table of Contents
Understanding Waver 1.0: ByteDance’s Universal Foundation Model
Waver 1.0 ByteDance represents a paradigm shift in generative AI architecture. Rather than following the industry standard of creating separate models for different tasks, ByteDance developed Waver 1.0 as a true universal foundation model—a single integrated framework capable of handling text-to-video (T2V), image-to-video (I2V), and text-to-image (T2I) generation within one cohesive system.
This “all-in-one” approach addresses a longstanding pain point in the AI video generation workflow. Previously, creators needed to juggle multiple specialized tools, each with its own learning curve, interface, and computational requirements. The fragmented ecosystem meant redundant training processes, inconsistent outputs, and a disjointed creative experience. Waver AI eliminates these friction points by building a holistic understanding of visual data where static images and dynamic videos exist along a unified spectrum.
The technical specifications are equally impressive. Waver 1.0 AI supports high-resolution output up to 1080p, with flexible aspect ratios and video lengths ranging from 2 to 10 seconds. This flexibility makes it suitable for everything from social media content to professional video production. The model’s 12 billion parameters enable nuanced understanding of complex prompts while maintaining efficient inference speeds.
Perhaps most notably, ByteDance video AI research has positioned Waver 1.0 among the elite. According to Artificial Analysis leaderboards (data as of August 5, 2025), Waver 1.0 secured a Top 3 ranking for both text-to-video and image-to-video generation tasks. Independent evaluations confirm that it consistently outperforms existing open-source alternatives and matches or exceeds state-of-the-art commercial solutions in motion quality, visual fidelity, and prompt adherence.
This isn’t just theoretical performance—it’s practical capability that translates directly into better creative outputs for real-world applications.
How Waver AI Works: The Technology Behind the Magic
Rectified Flow Transformers: The Core Innovation
At the heart of Waver 1.0 lies a sophisticated architectural choice that distinguishes it from most contemporary models: Rectified Flow Transformers. To appreciate why this matters, we need to understand the dominant approach it replaces.
Most generative AI models—including popular image and video generators—rely on diffusion processes. Diffusion works by gradually adding noise to training data, then learning to reverse this process. Think of it as sculpting a statue by starting with a rough block and slowly removing material. It’s effective, but computationally intensive, requiring many iterative steps to produce high-quality results.
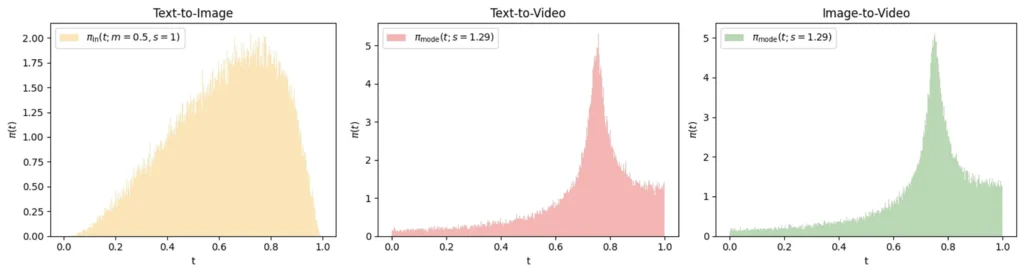
Rectified Flow takes a fundamentally different approach. Instead of learning a winding, multi-step denoising path, it learns to transform noise directly into data along the straightest possible trajectory. Imagine replacing a meandering country road with a direct highway—you reach the same destination much faster. This straight-line transformation in Waver 1.0 AI delivers several critical advantages: faster sampling speeds, more stable training dynamics, and greater computational efficiency—all essential for the demanding task of generating high-resolution video content.
Two-Stage Pipeline for Quality and Speed
Generating 1080p video directly from a text prompt is computationally expensive. Waver AI video generator sidesteps this challenge with an ingenious two-stage pipeline that optimizes both quality and speed.
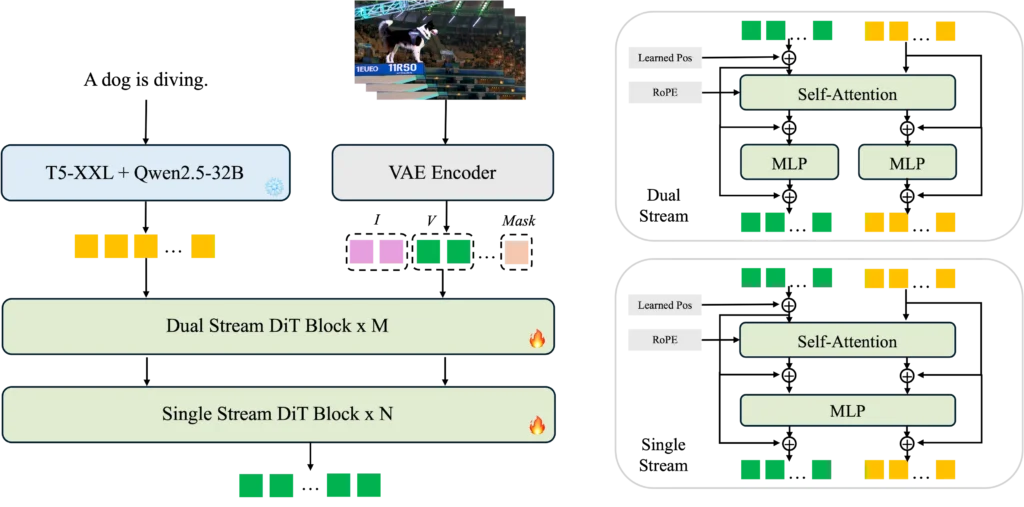
The first stage employs a “Task-Unified DiT” (Diffusion Transformer) module that generates base video content at 720p resolution. This core module is where the heavy lifting happens—interpreting prompts, establishing motion patterns, maintaining temporal consistency, and creating the fundamental visual content. By working at 720p rather than full 1080p, the model can allocate more computational resources to getting these foundational elements right.
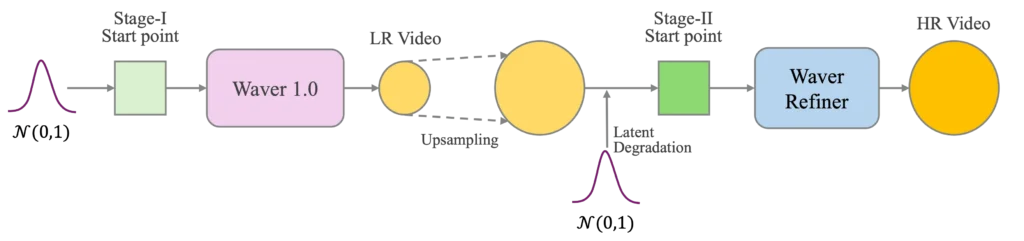
The second stage introduces the “Cascade Refiner,” a specialized module dedicated to upscaling. The Refiner takes the 720p output, upsamples it to 1080p, adds controlled noise, and then processes it to output pristine high-resolution video. Critically, the Refiner employs window attention mechanisms and requires only half the inference steps of the base model, significantly accelerating the process.
The numbers tell the story: this two-stage approach reduces inference time by approximately 40% for 720p-to-1080p upscaling compared to generating 1080p directly. For projects starting at 480p, the time savings jump to 60%. This architectural decision reflects practical engineering wisdom—sometimes the fastest path to a destination involves strategic waypoints.
Under the hood, Waver 1.0 leverages cutting-edge components throughout its pipeline. It uses Wan-VAE for efficient video latent compression, extracting text features through both flan-t5-xxl and Qwen2.5-32B-Instruct encoders. The video and text modalities are fused using a hybrid “Dual Stream + Single Stream” approach with 16 dual stream blocks and 40 single stream blocks, enabling sophisticated cross-modal understanding while maintaining computational efficiency.
Waver 1.0’s Creative Superpowers: Motion, Storytelling & Style
Complex Motion Mastery
One of the most persistent challenges in AI video generation has been creating believable, large-amplitude motion. Many models excel at subtle movements—gentle camera pans, slight character gestures—but struggle when asked to depict dynamic action. A basketball player executing a crossover dribble, a gymnast mid-flip, or a tennis player’s serve often look stiff, unnatural, or physically implausible in AI-generated content.
Waver 1.0 tackles this head-on. ByteDance’s research team created a specialized evaluation framework called the “Hermes Motion Testset” specifically to benchmark complex motion capabilities. This comprehensive dataset includes 96 carefully crafted prompts covering 32 distinct sports activities—tennis, basketball, gymnastics, rowing, boxing, equestrianism, and more. These aren’t easy scenarios; they represent some of the most challenging motion generation tasks in video AI.
The results from Waver AI on this benchmark are impressive. The model demonstrates superior motion amplitude—meaning it can depict large, sweeping movements without artifacts or unnatural poses. Equally important is its temporal consistency; motion flows smoothly from frame to frame without jarring jumps or physics violations. Whether it’s the explosive power of a boxer’s punch, the fluid grace of a rower’s stroke, or the complex coordination of a basketball crossover, Waver 1.0 captures the dynamism that brings these activities to life.
This capability extends beyond sports. Any scenario involving significant movement—dancing, running, elaborate camera movements, or dramatic action sequences—benefits from Waver’s enhanced motion modeling.
Multi-Shot Narrative Generation
Perhaps Waver 1.0’s most cinematically significant feature is its native multi-shot storytelling capability. Traditional AI video generators produce single, continuous shots—essentially individual clips. Creating a narrative sequence required generating multiple separate videos and manually editing them together, often struggling with consistency in character appearance, lighting, and style.
Waver AI video generator changes this fundamental limitation. The model can generate multi-shot videos within a single generation pass, allowing short narratives to flow seamlessly from scene to scene. A prompt might describe a character walking through a door (shot 1), moving through a hallway (shot 2), and entering another room (shot 3)—and Waver 1.0 will produce all three shots with consistent character features, coherent spatial relationships, and maintained atmospheric qualities.
This capability represents the first steps toward true AI-assisted filmmaking. Rather than simply generating stock footage clips, creators can now construct narrative sequences with intentional pacing, varied perspectives, and storytelling flow. The character who appears in the opening shot looks the same in the closing shot. The lighting mood established at the beginning carries through. The visual style remains coherent.
For content creators, marketers, and filmmakers, this dramatically reduces the post-production workload while opening new creative possibilities for AI-generated narrative content.
Diverse Style Generation
Visual style is fundamental to creative expression. A corporate explainer video demands photorealism; an indie music video might call for anime aesthetics; a children’s story needs whimsical illustration. Waver 1.0 delivers impressive stylistic versatility through a technique called “prompt tagging.”
During training, different styles of video data were explicitly labeled with descriptive tags. The model learned to associate these tags with distinct visual languages—the soft, dreamy quality of Studio Ghibli animation; the blocky, geometric look of voxel art; the smooth, expressive motion of Disney animation; the bold lines of 2D cartoon illustration. This explicit style teaching allows Waver 1.0 AI to understand not just what objects are, but how they should look in different artistic contexts.
In practice, creators can specify their desired aesthetic directly in the prompt. The same scene—”a man and woman walking hand in hand along a bustling city street at night”—can be generated in six dramatically different styles: photorealistic, Ghibli-inspired 2D animation, 3D animation, voxel-style 3D, Disney animated film aesthetic, or cartoon picture book style. Each version maintains the core narrative and composition while completely transforming the visual treatment.
This granular style control is invaluable for brand consistency, creative experimentation, and matching specific project requirements. Whether you’re creating content for social media, developing concept art, or prototyping animated sequences, having this range available within a single model streamlines the creative workflow considerably.
Waver 1.0 vs. The Competition: Where ByteDance Stands
The AI video generation market has become intensely competitive. Google’s Veo, Kuaishou’s Kling, Runway’s Gen-3, and even ByteDance’s own Seedance 1.0 all vie for dominance in this rapidly evolving space. So where does Waver 1.0 ByteDance fit in this crowded landscape?
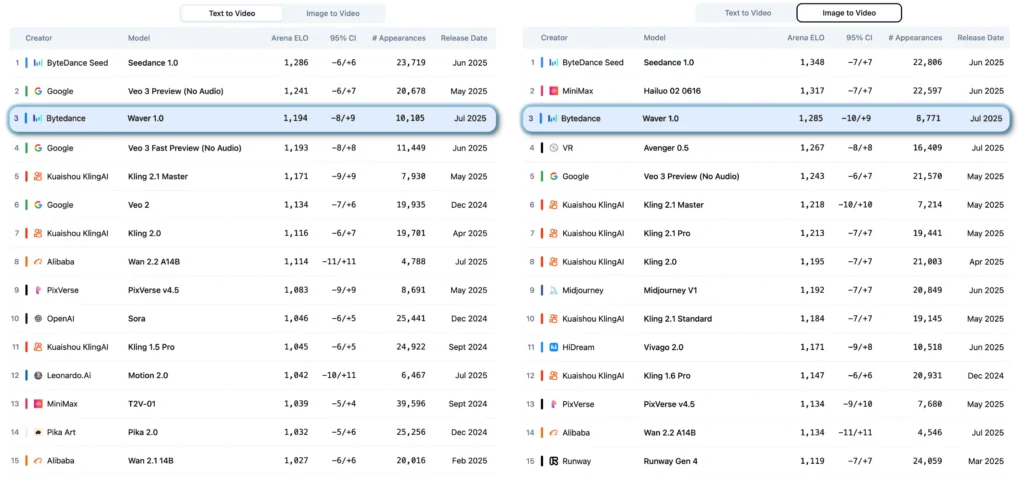
The answer lies partly in rigorous benchmarking. ByteDance developed “Waver-Bench 1.0,” a comprehensive evaluation dataset containing 304 samples spanning diverse scenarios: sports, daily activities, landscapes, animals, machinery, surreal scenes, and various animation styles. When compared against leading open-source and commercial models on this benchmark, Waver AI consistently demonstrated advantages in three critical dimensions: motion quality, visual fidelity, and prompt adherence.
The Hermes Motion Testset results are particularly telling. Where competing models often struggle with large-amplitude, complex movements, Waver 1.0 excels, producing more physically plausible and dynamically convincing action sequences. Manual evaluations positioned it ahead of both closed-source commercial solutions and open-source alternatives in capturing realistic motion.
On the independent Artificial Analysis leaderboard—a respected third-party benchmark—Waver 1.0 achieved Top 3 rankings for both text-to-video and image-to-video generation. This places it in elite company, performing comparably to models backed by massive computational resources and large research teams.
An interesting comparison point is ByteDance’s other recent release, Seedance 1.0. While both models emerge from the same parent company, they represent different strategic approaches. Seedance focuses on specific use cases and accessibility, while Waver 1.0 pursues technical excellence through unified architecture and advanced motion modeling. The coexistence of both models suggests ByteDance is exploring multiple paths forward in the video AI space.
One frequently discussed aspect of Waver 1.0 is its availability status. Early social media reports characterized it as “open source,” sparking excitement in the developer community. However, subsequent clarifications revealed a more nuanced picture: while the code architecture and research details are publicly available (the arXiv paper and GitHub repository are accessible), the model is “not open-weight.” This means the trained model weights—the billions of parameters that represent Waver’s learned knowledge—remain proprietary.
This hybrid approach is becoming increasingly common in AI research. It offers transparency to researchers who can study the architecture and training methodology, while maintaining commercial control over the actual deployable model. For the broader community, it means insights and techniques from Waver AI can inform other projects, even if the exact model isn’t freely redistributable.
The Future of AI Video Generation: How Gaga AI Leads the Next Wave
While Waver 1.0 represents a significant milestone in ByteDance’s video AI journey, the competitive landscape continues to evolve at breakneck speed. At the forefront of this innovation stands Gaga AI video generator, a free AI video generation platform that’s not just matching these advances—it’s surpassing them with capabilities that redefine what creators should expect from AI video tools.
GAGA-1: Cinema-Grade AI Video Generation
Powered by the GAGA-1 video model, Gaga AI delivers something truly revolutionary: cinema-grade performance that goes far beyond basic video generation. Where Waver 1.0 excels at visual synthesis and motion modeling, GAGA-1 video model introduces an entirely new dimension—synchronized audio-visual generation with Hollywood-level acting performance.
Film-Quality Character Performance
The GAGA-1 video model doesn’t just generate moving images; it creates performances. Characters speak with voices perfectly matched to their appearance and personality. Vocal tones capture subtle emotional nuances—excitement, hesitation, warmth, tension—bringing genuine feeling to every line. But the true magic lies in the “acting”: lip synchronization is absolutely precise, facial expressions are nuanced and contextually appropriate, and every gesture feels natural. This isn’t animation; it’s digital performance art that breathes authentic life into characters.
Audio-Visual Unity: The One-Step Solution
Traditional AI video workflows are frustratingly fragmented: generate video, add voiceover separately, match lip movements in post-production, layer in sound effects. Gaga AI video generator obliterates this complexity with synchronized audio-visual generation. The model produces dialogue with perfectly matched lip movements, voices that harmonize with character design and scene atmosphere, plus comprehensive environmental and action sound effects—all in a single generation. The output is production-ready cinema-grade content, eliminating tedious multi-step workflows entirely.
Two-Person Scene Mastery
While many AI video models struggle with multiple characters, GAGA-1 excels at generating authentic two-person dialogue scenes within a single frame. Whether it’s a dual interview, a dramatic conversation, or interactive storytelling, the model maintains visual and audio consistency for both characters simultaneously. This capability unlocks deeper, more complex narratives that feel genuinely cinematic.
Global Language Support with Native-Level Accuracy
The Gaga AI video generator supports multiple languages with remarkable authenticity. Each language features native-level lip synchronization and genuine emotional expression—not translations that feel robotic or forced, but performances that capture the natural cadence and cultural nuance of each tongue. For global content creators, this multilingual mastery removes major localization barriers.
Technical Excellence Meets Practical Accessibility
GAGA-1 video model matches or exceeds Waver 1.0’s core capabilities while adding its unique audio-visual innovations:
- 1080p high-resolution output for professional-quality production
- 10-second video generation with complete narrative arcs
- Flexible aspect ratios (16:9 and 9:16) optimized for both horizontal and vertical content
- Rapid generation speeds that keep creative momentum flowing
- AI avatar video creation for consistent character-driven content
- Voice cloning technology for personalized vocal performances
- AI lip sync precision that eliminates the “uncanny valley”
- Image-to-video transformation bringing static visuals to dynamic life
- Text-to-speech integration with natural, expressive delivery
Most remarkably, Gaga AI video generator offers all these advanced capabilities completely free. Where proprietary models like Waver 1.0 and Seedance 1.0 demonstrate technical possibility, Gaga AI ensures that possibility becomes accessible reality.
The Competitive Ecosystem
The landscape also includes platforms like Magi AI video generator, which leverages the Magi-1 video model to serve specialized creative needs. This healthy competition drives continuous innovation across temporal consistency, prompt adherence, audio-visual synchronization, and creative control.
Yet Gaga AI video generator stands apart through its commitment to removing barriers. While Waver AI represents cutting-edge research and ByteDance video AI explores multiple architectural approaches, Gaga AI focuses on practical deployment—ensuring indie filmmakers, content creators, marketing professionals, educators, and hobbyists can harness state-of-the-art capabilities without prohibitive costs, complex technical requirements, or fragmented workflows.
The Industry’s Direction
The trajectory is unmistakable: AI video generation is moving toward unified, efficient, increasingly powerful frameworks that don’t just create footage but craft complete audio-visual experiences. Whether it’s ByteDance’s exploration with Waver 1.0 and Seedance, or next-generation solutions like GAGA-1 and Magi-1, the future belongs to platforms combining three critical elements: technical excellence, creative flexibility, and user accessibility.
For creators ready to explore this frontier today, the Gaga AI video generator offers an immediate, zero-cost entry point into professional AI video generation—proof that transformative technology reaches its full potential only when accessible to everyone.
Take Home
Waver 1.0 marks a pivotal moment in the evolution of AI video generation. ByteDance’s decision to build a unified, multi-task foundation model rather than pursuing incremental improvements to existing approaches demonstrates genuine architectural innovation. The combination of rectified flow transformers, intelligent two-stage processing, superior motion modeling, and native multi-shot capabilities positions Waver 1.0 ByteDance as a technical tour de force that raises the bar for the entire industry.
Yet technology advances most powerfully when it becomes accessible. The breakthroughs pioneered by models like Waver AI illuminate the path forward, but platforms like Gaga AI video generator actually walk that path, putting cutting-edge capabilities into creators’ hands without barriers. As the GAGA-1 video model and competitors like Magi-1 continue advancing what’s possible, the real winners are creators everywhere who gain increasingly powerful tools for visual storytelling.
The future of video creation isn’t just about better AI models—it’s about making those models work for everyone. Whether you’re a professional filmmaker exploring new creative workflows, a marketer seeking compelling visual content, or a hobbyist bringing imaginative ideas to life, this new generation of AI video tools is reshaping what’s possible.
Ready to experience the next generation of AI video creation? Try Gaga AI video generator today and discover how free, accessible AI is transforming visual storytelling for creators worldwide.
The wave of innovation isn’t slowing down—it’s accelerating. And the most exciting chapters of this story are still being written.
Resources & Links:
- Waver 1.0 Research Paper: arXiv:2508.15761
- GitHub Repository: FoundationVision/Waver
- Try Gaga AI Video Generator: Visit Gaga AI Platform
Related Posts:
 Google Veo 3.1 vs. Sora 2: Sound, Physics, and the Next Generation of AI Video
Google Veo 3.1 vs. Sora 2: Sound, Physics, and the Next Generation of AI Video
 Kling O1: Complete Guide to the World’s First Unified Multimodal Video Generation Model (2026)
Kling O1: Complete Guide to the World’s First Unified Multimodal Video Generation Model (2026)
 Seedance 1.0: Bytedance’s Breakthrough AI Video Model Explained
Seedance 1.0: Bytedance’s Breakthrough AI Video Model Explained
 PixVerse AI Review 2026: Features, Pricing & Best Alternatives
PixVerse AI Review 2026: Features, Pricing & Best Alternatives