
Key Takeaways
Qwen-Image-2.0 is Alibaba’s newest image generation model that combines professional text rendering with photorealistic image creation in a single 7B parameter architecture. The model supports native 2K resolution (2048×2048), processes up to 1,000-token instructions for complex compositions, and unifies both generation and editing capabilities without requiring separate pipelines.
Core capabilities:
- Professional typography engine with multi-script support
- Native 2K resolution for microscopic detail rendering
- Unified generation + editing in one 7B model
- Support for 1K-token complex instructions
- Advanced photorealism for people, nature, and architecture
Table of Contents
What Is Qwen-Image-2.0?
Qwen-Image-2.0 is a foundational image generation model released by Alibaba’s Qwen team in February 2026. Unlike previous AI image generators that struggle with text or require separate models for editing, Qwen-Image-2.0 delivers both capabilities in a single unified architecture.
The model represents a significant efficiency leap: it’s a 7B parameter model (down from the 20B parameters in Qwen-Image v1) while delivering superior performance on both text-to-image generation and image-to-image editing benchmarks.
What makes it different: Most AI image generators either excel at photorealism or text rendering, but rarely both. Qwen-Image-2.0 simultaneously delivers pixel-perfect text placement and photorealistic imagery, making it practical for professional design work like presentations, infographics, and marketing materials.
Five Core Strengths of Qwen-Image-2.0
1. Precision: Pixel-Perfect Text Rendering
Qwen-Image-2.0 excels at accurately rendering text within images. The model can generate professional presentation slides, posters, and infographics with correctly spelled text in multiple languages and writing systems.
What you can create:
- PowerPoint slides with complex layouts
- Movie posters with multiple text layers
- Chinese calligraphy in authentic styles (regular script, cursive, Slender Gold)
- Bilingual travel posters with aligned text blocks
- Comic panels with speech bubbles
Example capability: The model can render an entire timeline presentation showing the evolution of the Qwen-Image product line, including accurate text labels, dates, and picture-in-picture compositions showing before/after editing examples—all generated from a single detailed prompt.
2. Complexity: 1K-Token Instruction Support
Unlike most image generators limited to short prompts, Qwen-Image-2.0 processes instructions up to 1,000 tokens long. This enables intricate multi-element compositions that would be impossible with simpler models.
Complex generation examples:
- A/B testing result reports with statistical tables, charts, and annotations
- Multi-day travel itineraries with detailed scheduling
- 4×6 grid comic strips with consistent characters across 24 panels
- Detailed infographics combining data visualization and explanatory text
Practical workflow: Users can leverage large language models (LLMs) to expand simple ideas into detailed 1K-token prompts. For example, “generate a hand-drawn Hangzhou travel poster” can be expanded by an LLM into a comprehensive description that Qwen-Image-2.0 then renders with all specific details intact.
3. Aesthetics: Professional Layout & Composition
The model understands visual design principles, automatically positioning text in blank areas to avoid obscuring main visual subjects. It handles multiple calligraphic styles and maintains proper text-image relationships.
Design intelligence:
- Text placement that preserves visual hierarchy
- Multiple calligraphy styles (regular script, Slender Gold, cursive)
- Classical Chinese painting composition with integrated poetry
- Modern infographic layouts with balanced white space
Real-world application: When generating a Chinese ink painting with accompanying poetry, the model writes text vertically in appropriate calligraphic style while ensuring it doesn’t overpower the painted scene—achieving the traditional “poetry, calligraphy, and painting unity” aesthetic.
4. Realism: Photorealistic Rendering
Qwen-Image-2.0 delivers photorealistic quality with attention to material properties, lighting, reflections, and perspective. Text appears naturally integrated into scenes rather than appearing pasted on.
Photorealism features:
- Accurate material rendering (glass whiteboards, fabric, paper)
- Realistic lighting and shadow interactions
- Proper perspective distortion for angled text
- Natural reflections and optical properties
- Microscopic detail on skin, fabric, and architecture
Advanced example: The model can generate a photo of someone writing on a glass whiteboard with the Great Wall visible through windows behind them. The text on the whiteboard appears with natural handwriting imperfections, the glass shows realistic reflections, and the photographer’s reflection appears in the corner—all from a single text prompt.
5. Alignment: Structured Organization
For complex multi-element compositions, Qwen-Image-2.0 maintains precise alignment. Calendar grids, comic panel layouts, and table structures remain organized and readable.
Alignment capabilities:
- Calendar grids with correct date placement
- Multi-panel comic layouts (4×6 grids with 24 panels)
- Infographic tables with aligned columns
- Timeline visualizations with synchronized elements
Qwen-Image-2.0 Use Cases & Applications
1. Professional Design & Marketing
Presentation creation: Generate complete PowerPoint slides with charts, diagrams, and formatted text. The model handles complex layouts including dual-track timelines, comparison tables, and annotated flowcharts.
Marketing materials: Create posters, flyers, and social media graphics with accurate brand text, product names, and calls-to-action. The unified editing capability allows quick iterations without switching tools.
Infographics: Produce data visualization combining statistics, charts, and explanatory text. The 1K-token instruction capacity enables complex multi-section infographics in a single generation.
2. Content Creation & Entertainment
Comic generation: Create multi-panel comics (up to 4×6 grids with 24 panels) with consistent characters, speech bubbles, and narrative flow. The model maintains character consistency across panels.
Educational materials: Generate illustrated guides, calendars with cultural annotations, and instructional diagrams with clear labeling.
Creative writing: Produce illustrated poetry with calligraphy, movie poster mockups, and artistic compositions combining text and imagery.
3. Image Editing & Enhancement
Text overlay: Add text to existing photos with natural integration—inscribe poetry onto landscapes, add captions to portraits, or overlay instructions on product images.
Multi-image composition: Combine elements from multiple source images into cohesive compositions. Merge portraits into unified group photos or create before/after comparisons.
Cross-dimensional editing: Integrate cartoon elements into realistic photos or add graphic overlays to photographic backgrounds.
How to Use Qwen-Image-2.0
Access Options
Qwen Chat (Free Demo): Available immediately at qwen.ai for testing. No API key required—use the web interface to experiment with prompts and see real-time results.
Alibaba Cloud API (Invite Beta): Professional access through Alibaba Cloud’s API service. Currently in invite-only beta phase with broader release expected soon.
Open-Source Weights (Coming Soon): Based on Alibaba’s track record with Qwen-Image v1 (released open-source under Apache 2.0 one month after launch), community expects weights release in Q1 2026.
Prompting Best Practices
Start detailed for complex scenes: The 1K-token capacity means you can be thorough. Describe layout, colors, text content, positioning, and style preferences in a single prompt.
Use LLMs for prompt expansion: Feed simple ideas to ChatGPT or Claude with instructions to expand into detailed visual descriptions. Qwen-Image-2.0 will render the comprehensive prompt accurately.
Specify text exactly: For text rendering, include exact wording, language, font style, and placement. The model follows instructions precisely.
Leverage multimodal understanding: Describe relationships between elements (“text positioned in upper-left blank area,” “speech bubble pointing to character on right”) and the model will understand spatial context.
Generation Workflow Example
- Concept: “Create a Chinese travel itinerary poster”
- LLM expansion: Use ChatGPT/Claude to expand into detailed 500-800 token description specifying locations, times, visual style, text placement
- Generation: Submit expanded prompt to Qwen-Image-2.0
- Review: Evaluate text accuracy, layout, and overall composition
- Edit (if needed): Use the same model’s editing capability to refine specific elements
Qwen-Image-2.0 vs. Competitors
Qwen-Image-2.0 vs. DALL-E 3
Text rendering: Qwen-Image-2.0 significantly outperforms DALL-E 3 on complex text, especially non-Latin scripts. DALL-E 3 struggles with accurate multi-line text and non-English languages.
Prompt complexity: Qwen-Image-2.0’s 1K-token capacity vs. DALL-E 3’s shorter prompts enables more detailed instructions.
Model size: At 7B parameters with native 2K output, Qwen-Image-2.0 is more efficient for potential local deployment.
Unified editing: Qwen-Image-2.0 handles generation and editing in one model; DALL-E 3 focuses primarily on generation.
Qwen-Image-2.0 vs. Stable Diffusion 3
Text accuracy: Qwen-Image-2.0’s text rendering exceeds current Stable Diffusion 3 capabilities, particularly for complex layouts and non-Latin scripts.
Architecture: SD3’s diffusion transformer vs. Qwen’s encoder-decoder architecture with Qwen3-VL encoder provides superior multimodal understanding.
Accessibility: Stable Diffusion 3 available open-source; Qwen-Image-2.0 currently API-only with expected open release.
File size: 7B parameters makes Qwen-Image-2.0 competitive for consumer hardware deployment once weights release.
Qwen-Image-2.0 vs. Midjourney
Text rendering: Midjourney traditionally weak on text; Qwen-Image-2.0 designed specifically for accurate typography.
Professional layouts: Qwen-Image-2.0 better for infographics, presentations, posters requiring precise text.
Artistic style: Midjourney excels at artistic interpretation; Qwen-Image-2.0 focuses on accuracy and photorealism.
Editing capability: Qwen-Image-2.0’s unified editing stronger than Midjourney’s vary/remix features.
Frequently Asked Questions
Is Qwen-Image-2.0 available for free?
Yes, through the Qwen Chat demo at qwen.ai. The free web interface allows testing without API keys. For production use, Alibaba Cloud API access is currently in invite-only beta with commercial pricing TBD.
When will open-source weights be released?
Not officially announced, but Qwen-Image v1 was released open-source (Apache 2.0) approximately one month after initial announcement. Community expects similar timeline for v2.0, likely Q1 2026.
Can Qwen-Image-2.0 edit existing images?
Yes—it’s a unified generation and editing model. Upload an image and provide editing instructions (add text, modify elements, combine with other images) and the same model handles both tasks.
What languages does it support for text rendering?
Demonstrated strong support for English and Chinese (including multiple calligraphic styles). Multilingual capability extends to other languages, though Chinese and English show the most comprehensive testing.
How does it compare to Midjourney for commercial work?
For projects requiring accurate text (presentations, infographics, marketing materials), Qwen-Image-2.0 is superior. For purely artistic work without text requirements, Midjourney’s aesthetic interpretation may be preferred. Consider your specific use case.
Can I run it locally on consumer hardware?
Not yet—waiting for open-source release. Once weights drop, the 7B parameter size should run on high-end consumer GPUs (24GB VRAM recommended, possibly 16GB with optimization).
Does it support batch generation?
Through the API, yes. The Qwen Chat web demo processes single images. API access enables automated batch workflows for professional production.
What’s the maximum image resolution?
Native 2K (2048×2048 pixels). This provides excellent detail for most professional use cases including print materials and digital displays.
How accurate is text spelling?
Very high accuracy when text is specified exactly in prompts. For best results, include exact text content rather than describing what text should say—the model follows instructions precisely.
Bonus: Transform Images to Videos with Gaga AI
While Qwen-Image-2.0 excels at image generation, Gaga AI extends creative possibilities into video production. This image-to-video AI platform complements Qwen-Image-2.0’s outputs perfectly:
Gaga AI Video Generator Features
Image-to-Video AI: Upload Qwen-Image-2.0 generated images and animate them into dynamic videos. Transform static infographics into motion graphics, bring illustrations to life, or create presentation videos from generated slides.
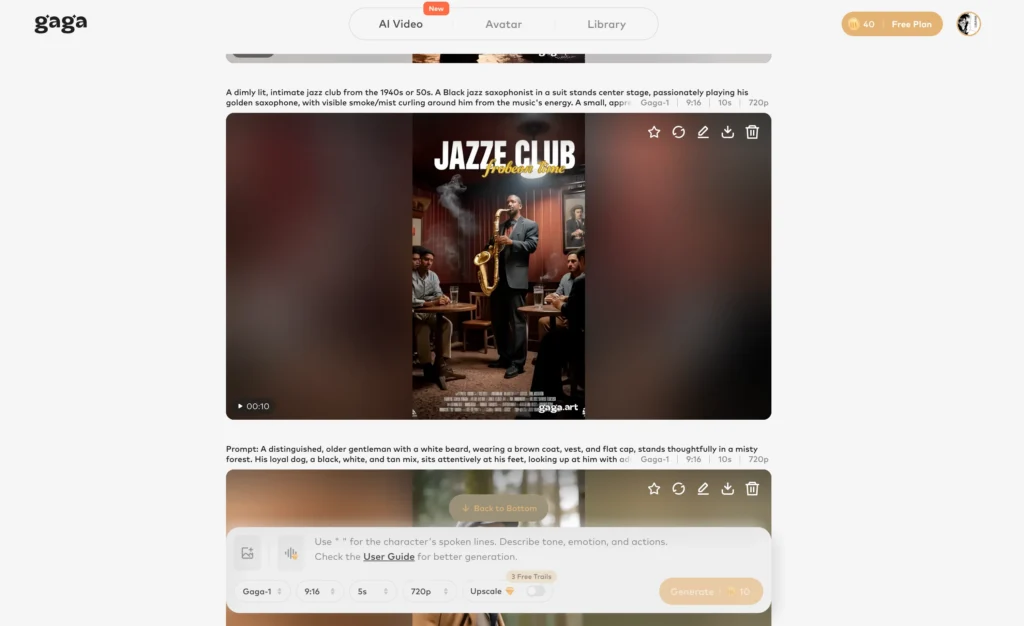
Video and Audio Infusion: Combine multiple video clips, add background music, and sync audio with visual elements. Perfect for creating marketing videos from Qwen-Image-2.0 generated assets.
AI Avatar Integration: Add realistic AI-generated avatars to present your content. Ideal for educational materials, corporate presentations, and social media content using Qwen-Image-2.0 backgrounds.
AI Voice Clone & Text-to-Speech: Generate natural voiceovers in multiple languages. Clone your voice or use TTS to narrate content over Qwen-Image-2.0 generated visuals.
Workflow: Qwen-Image-2.0 + Gaga AI
- Generate base images with Qwen-Image-2.0 (infographics, scenes, characters)
- Import to Gaga AI for animation and video production
- Add AI avatars to present content
- Apply voice synthesis for narration
- Export final video with professional quality
This combination enables complete multimedia content production: Qwen-Image-2.0 for pixel-perfect static assets, Gaga AI for bringing them to life with motion and audio.
Conclusion: The Future of AI Image Generation
Qwen-Image-2.0 represents a significant advancement in AI image generation by successfully unifying professional text rendering with photorealistic image creation in an efficient 7B parameter architecture. The model’s 1K-token instruction capacity, native 2K resolution, and dual generation-editing capability position it as a practical tool for professional creative work.
Key advantages:
- First model to deliver both pixel-perfect text and photorealism at production quality
- Unified architecture eliminates need for separate generation and editing pipelines
- Efficient 7B parameters enable potential consumer hardware deployment
- Demonstrated excellence on Chinese calligraphy and multi-script support
Looking forward: The anticipated open-source release will likely accelerate adoption in creative workflows, ComfyUI integrations, and local deployment scenarios. For professionals requiring accurate text in generated images—from presentations to marketing materials—Qwen-Image-2.0 establishes a new capability benchmark.
The model is available now at qwen.ai for testing, with API access expanding through Alibaba Cloud.



