Paper: https://arxiv.org/pdf/2601.10611
Code: https://github.com/allenai/molmo2
Demo: https://playground.allenai.org/?model=molmo2-8b
Models: Molmo2-4B | Molmo2-8B | Molmo2-O-7B
Data: https://huggingface.co/collections/allenai/molmo2-data
Key Highlights
Introducing the Molmo2 Model Family
This work presents Molmo2, a series of open-source vision-language models (VLMs) designed to achieve state-of-the-art performance in the open-source domain. Molmo2 demonstrates exceptional point-driven grounding capabilities across single-image, multi-image, and video tasks.
Large-Scale, High-Quality Open-Source Datasets
The release includes a comprehensive collection of novel, high-quality datasets: 7 video datasets and 2 multi-image datasets. What makes these datasets unique is their complete independence from synthetic data generated by proprietary VLMs, providing the open-source community with transparent and trustworthy training resources. These include highly detailed video captioning datasets for pretraining, free-form video question-answering datasets for fine-tuning, novel object tracking datasets with complex queries, and innovative video pointing datasets.
Innovative Training Methodology
The research proposes an efficient training scheme that leverages advanced packing and message tree encoding to optimize data processing. Additionally, Molmo2 applies bidirectional attention mechanisms on visual tokens and employs a novel token weighting strategy, all of which significantly enhance model performance.
Leading Performance
Molmo2 achieves outstanding results across multiple key benchmarks. In short videos, counting, and captioning, Molmo2 reaches state-of-the-art levels among open-source models. For video grounding tasks, Molmo2 significantly outperforms existing open-source models (like Qwen3-VL) and even surpasses proprietary models (like Gemini 3 Pro) in certain tasks, particularly in video pointing and video tracking.
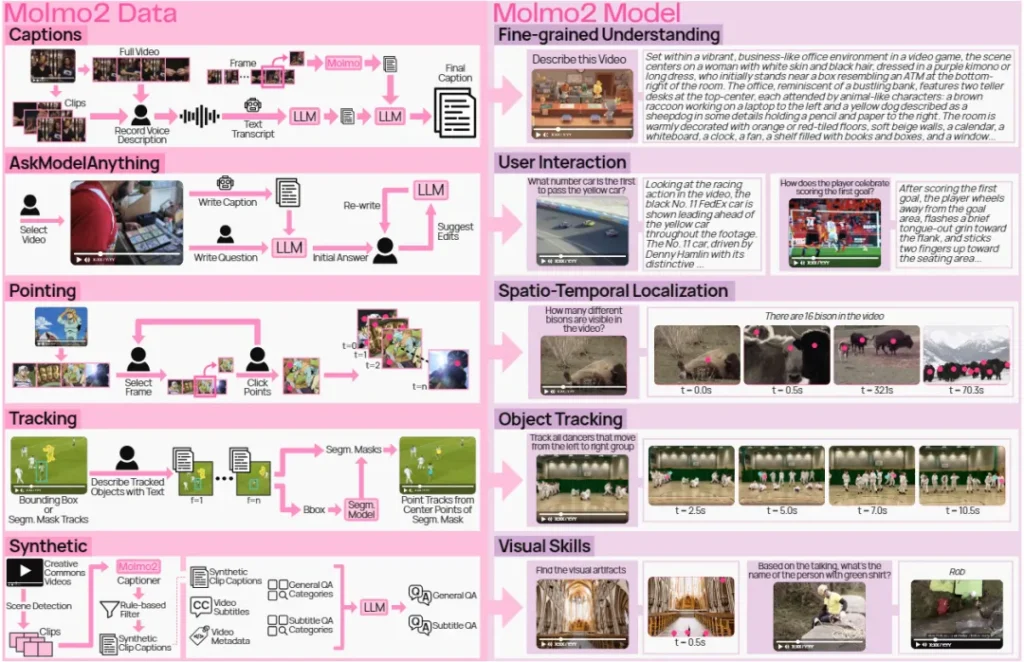
Figure 1: Molmo2 is trained on one of the largest fully open-source video-centric multimodal corpora to date, including nine new datasets for dense video captioning, long-form video QA, and open-vocabulary pointing and tracking on images, multiple images, and videos. Molmo2 accepts single images, image sets, and videos as input, generating both free-form language and spatial outputs like spatiotemporal points, object trajectories, and temporally grounded chains of thought that localize objects and events. Across various video-language and grounding benchmarks, Molmo2 matches or exceeds previous open-source models trained on proprietary systems while remaining fully open.
Table of Contents
Summary Overview
Problems Addressed
- The most powerful video-language models (VLMs) are predominantly proprietary, limiting progress in the open-source community
- Existing open-source models either rely on knowledge distillation from synthetic data generated by proprietary VLMs or don’t disclose their training data and methods, leaving the open-source community without foundations to improve upon state-of-the-art VLMs
- Many downstream applications require not just high-level video understanding but also “grounding” capabilities—the ability to localize targets through pointing or pixel tracking—which even proprietary models often lack
Proposed Solution
- Introduces Molmo2, a new VLM family designed to be state-of-the-art among open-source models
- Contributes a series of novel datasets: 7 video datasets and 2 multi-image datasets, collected entirely without reliance on closed VLMs
- Proposes efficient packing and message tree encoding training schemes for the data
Applied Techniques
- Adopts an architecture combining pretrained LLMs with Vision Transformers (ViT) through connector modules
- Introduces bidirectional attention mechanisms on visual tokens
- Employs a novel token weighting strategy to balance training across tasks with varying output lengths
- Develops on-the-fly packing algorithms to efficiently handle training examples of different lengths
- Uses message trees to encode videos and images with multiple annotations
Achieved Results
- Demonstrates exceptional point-driven grounding capabilities across single-image, multi-image, and video tasks
- Achieves SOTA performance among open-source models, particularly excelling in short videos, counting, and captioning
- Significantly outperforms existing open-source models in video grounding tasks (e.g., Molmo2 achieves 35.5% vs Qwen3-VL’s 29.6% on video counting accuracy)
- Even surpasses proprietary models in certain tasks (e.g., Molmo2 achieves 38.4% vs Gemini 3 Pro’s 20.0% on video pointing F1 score, and 56.2% vs 41.1% on video tracking J&F score)
- Ranks equal to or better than other open-weight models like Llama3-V and Qwen3-VL in human preference evaluations, far exceeding previous fully open-source models
- Outperforms all other models on the Point-Bench leaderboard for image pointing tasks, including the latest specialized pointing model Poivre
Training
Architecture
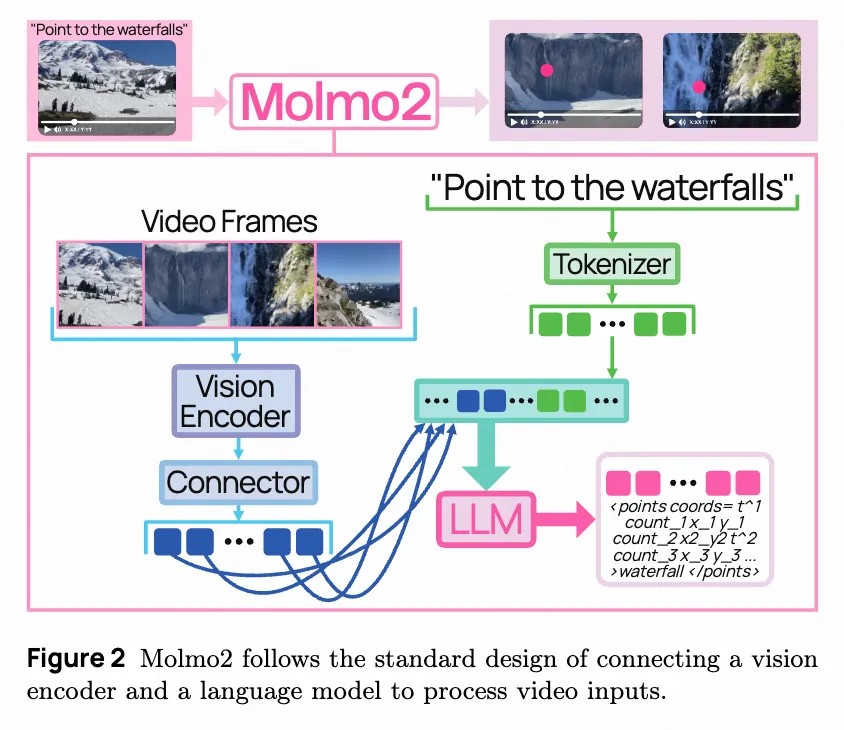
Molmo2’s model architecture follows the common design of combining pretrained LLMs with Vision Transformers (ViT) through connector modules. Visual inputs are segmented or resized into fixed-size crops and encoded by ViT into patch-level features. These patch-level features are then pooled and projected through the connector, passed as visual tokens along with any text input to the LLM, as illustrated in Figure 2.
Cropping
For input images, the research uses a single crop of the scaled image plus up to K overlapping crops to tile the image for higher-resolution processing. Images that cannot be tiled with K crops are scaled. During training, K = 8; during inference, K = 24. For videos, frames are sampled at S = 2 fps as single crops (scaled if necessary) to reduce computational costs when processing long videos. The maximum frame count is set to F = 128 (F = 384 for long-context training). If video length exceeds F/S, F frames are uniformly sampled. In both cases, the last frame is always included since most video players display it after playback ends, making it potentially important to users.
Vision-Language Connector
The connector uses features from the third-to-last and ninth-to-last layers of the ViT, following literature conventions. For images, 2×2 patch windows are pooled into single vectors through multi-head attention layers, with the mean of patches serving as the query. For video frames, 3×3 patch windows are used to reduce token count. The same shared parameters are used for both image and video frame pooling connectors. Finally, pooled features are projected using a shared MLP.
LLM
The LLM takes as input visual tokens interleaved with text timestamps (for videos) or image indices (for multi-image inputs). For multi-crop images, column tokens are included to indicate image aspect ratios. Column tokens are not included for single-crop images as they’re always square. Image and frame start tokens are also added, with captions (marked with text timestamps) included as text after visual inputs when available. Image tokens (even from different frames/images) are allowed to forward-attend to each other, which the research found improves performance.
Training Process
The research employs a simple three-stage design: a lightweight image-only pretraining stage, joint video/image supervised fine-tuning (SFT), followed by a short-term long-context SFT stage. Training is conducted on Molmo2 data, PixMo image data, and various open-source datasets.
Pretraining
The pretraining stage includes length-conditioned dense captioning and transcription prediction using PixMo-Cap. NLP data from Tulu’s supervised fine-tuning data (filtered for non-English content and code) is added to better preserve language capabilities. Additionally, pointing data from PixMo-Points, PixMo-Count, and CoSyn-Point is incorporated. The research found that adding pointing data during pretraining yields better and more stable pointing performance. A mixing ratio of 60% captioning, 30% image pointing, and 10% natural language is used. Training runs for 32k steps with batch size 128, resulting in approximately 4 epochs on PixMo-Cap. All parameters are fine-tuned with separate learning rates for ViT, connector, and LLM.
SFT
The data mixture combines PixMo, Molmo2 datasets, Tulu, and other open-source video and image datasets. These datasets are categorized, with sampling rates manually assigned based on empirical testing for each category (as shown in Table 1). Within each category, datasets are sampled proportionally to the square root of each dataset’s size, with some manual rebalancing, such as downsampling large synthetic datasets. Training runs for 30k steps with batch size 128 and maximum sequence length of 16,384.
Long-Context SFT
Finally, a third training stage uses the same SFT data mixture with longer context lengths. In this stage, sequence length increases to 36,864, F = 384 is set, training runs for 2k steps, and context parallelism (CP) is used on the LLM so each example is processed by a group of 8 GPUs. Ulysses attention is used for LLM context parallelism as its all-gather provides flexibility for custom attention masks used by the packing and message tree system. Video frame processing after vision encoder and attention pooling is also distributed across each context parallel group, proving highly effective in reducing model memory footprint. Long-context training is only used as a short final training stage due to significant training overhead.
Pointing and Tracking
A compressed plain-text format represents point coordinates, including normalized x and y coordinates, timestamps (for videos) or image indices (for images), and unique integer IDs for each distinct object for tracking and counting. Points are sorted by time/image index, then by x, y coordinates. During SFT, up to 24 crops instead of 8 are used for 30% of images with pointing annotations to ensure pointing generalizes to high-resolution images. For video pointing, training uses examples with up to 60 point annotations. Multi-turn conversations are also constructed and trained for the same video with multiple pointing or counting queries. For tracking, auxiliary tasks are added that only predict the first and last frames where objects appear, or track from input queries and points.
Token Weighting
The data includes multiple-choice questions with single output tokens and long video captions with over 4,000 output tokens. These long output examples can easily dominate loss tokens even with low sampling frequencies, potentially degrading performance on short-answer or multiple-choice tasks. As a solution, weights for certain examples are adjusted when used for loss calculation. A fixed weight of 0.1 is used for video captions and 0.2 for pointing, as both tasks can have very long, dense outputs. For other tasks, a heuristic approach is followed where n is the number of answer tokens, better balancing long and short output training examples.
Packing
Example token counts range from a few hundred (plain text or small images) to over 16k (videos with captions or long videos during long-context training). To avoid wasting padding when creating training batches, packing is used to combine multiple short examples into one long sequence. Packing is non-trivial for vision-language models due to the need to efficiently pack both ViT crops and LLM tokens, and support models with different image/video transformation token methods. An on-the-fly packing algorithm was developed that builds maximally efficient packed sequences from examples in a small memory buffer, integrating into standard PyTorch data loaders.
Message Trees
Videos and images with multiple annotations are encoded as message trees. Visual inputs are encoded as the first message, with each annotation becoming a different branch. The tree is linearized into a single sequence with custom attention masks preventing branches from cross-attending to each other. On average, examples in the data have 4 annotations, and packing can fit 3.8 samples into 16,348 token sequences during SFT, achieving 15x training efficiency. Figure 3 illustrates the attention masking.
Experiments
The following sections cover various evaluations of Molmo2 models, including overall performance, grounding capabilities, and image results.
Overall Performance
For the human preference study, questions were collected from human annotators and manually filtered to prioritize open-ended over direct questions, yielding 450 questions. 51 videos were added for captioning queries. Outputs from two models were sampled, and annotators provided pairwise preference evaluations. Over 105,000 ratings were collected (501 per model pair). Bradley-Terry models were used to calculate Elo rankings from this data.
During inference, 384 frames and greedy decoding are used. For human evaluation and video captioning, top_p=0.95, temperature=0.7, and frequency_penalty=0.1 are used, producing more natural results when generating long outputs.
Results are shown in Table 2, with several key findings:
- Molmo2 achieves state-of-the-art performance among non-proprietary models in short video benchmarks, captioning, and counting
- Molmo2 outperforms previous fully open-source models but lags behind the best open-weight models. This is attributed to the lack of open-source long (10+ minute) training data and computational constraints making extensive ultra-long context training difficult
- Molmo2 ranks equal to or better than other open-weight models like Llama3-V and Qwen3-VL in human preference and far exceeds previous fully open-source models
Grounding Results
Video Counting and Pointing
For counting, evaluation is also conducted on BURST-VideoCount, a counting benchmark of 2.2k examples extracted from BURST test set ground truth trajectories. The “close accuracy” metric is reported (considered correct if the prediction is close to the ground truth), rewarding predictions near the correct answer. For pointing, Molmo2-VideoPointVal (Molmo2-VP) was constructed by running SAM 2 to collect object segmentation masks around spatiotemporal points annotated in Molmo2-VideoPoint within 3-second windows, manually filtering examples with incorrect masks, yielding 181 examples. For video pointing, F1, recall, and prediction metrics are reported, measuring how well generated points match ground truth masks.
Table 3 shows the results. Molmo2 performs excellently on the close accuracy metric, surpassing GPT-5. For Molmo2-VP, prompts were carefully tuned and point and bounding box formats were tried for baseline models; however, no recipe achieving very strong performance was found. Gemini 3 Pro achieved the best score, but Molmo2 still significantly outperforms it.
Video Object Tracking
Video tracking is evaluated on referring video object segmentation (VOS) benchmarks, where a point is considered correct if it falls within the ground truth segmentation mask. Molmo2-Track was also introduced, a benchmark covering more diverse domains with complex object motion and occlusions to evaluate Molmo2’s performance in more challenging and realistic tracking tasks (see appendix for details). Following standard practices, SAM 2 is used to convert point predictions to segmentation masks for evaluation. Jaccard and F-measure (J&F) metrics are reported to measure segmentation quality across all frames, along with F1 scores for 1 fps points. For API models, bounding boxes are generated and their center points extracted, as they cannot generate accurate points.
Tables 4-5 show the results: (1) Molmo2 outperforms all baselines across all benchmarks, including specialized segmentation models (gray sections), particularly excelling on ReasonVOS and Molmo2-Track, which require complex reasoning and occlusion handling capabilities. (2) Gemini 2.5 Pro is the strongest API model, but it still struggles to generate accurate object trajectories.
Image Results
Table 6 presents results for image and multi-image benchmarks. Following Molmo’s evaluation protocol, the same 11-benchmark average is reported for single-image benchmarks. As with videos, all model results were tested independently when needed.
Overall, Molmo2 robustly outperforms previous open-data models. Molmo2 slightly trails the best open-weight models on OCR-intensive benchmarks (like DocVQA or InfoQA) but excels on general question-answering tasks, including achieving state-of-the-art performance on VQA v2.0 and RealWorldQA (RWQA). Counting is also a strength, especially on the challenging PixMo-Count test set. However, Molmo2 lags on open-weight reasoning benchmarks (MathVista, MMMU), likely due to lack of multimodal reasoning training data.
On multi-image tasks, Molmo2 is competitive with most open-weight models, except GLM-4.1V-9B, which clearly leads all other models.
Image pointing was evaluated on Point-Bench, with results shown in Table 7. Molmo2 surpasses all other models on the Point-Bench leaderboard, including the recent specialized pointing model Poivre. The improvement in pointing capability is attributed to the enhanced vision encoder, pointing pretraining, and token weighting.
Ablation Studies and Specialized Models
Next, ablation experiments were conducted on the model, training strategy, and data. To avoid the high computational cost of training full models, specialized 4B models were trained on data subsets for ablation experiments. These tables use gray rows to show specialized models with default settings.
Video Ablations
Table 8 shows results and ablations for video-only and video-captioning-only data. Video QA data has a positive transfer effect on captioning (Table 8a), and vice versa (Table 8c). Table 8b shows that both bidirectional attention and token weighting improve QA performance, though token weighting slightly reduces captioning performance. Meanwhile, removing frame timestamps degrades both metrics, indicating that including temporal information is important, especially for captioning. Increasing video pool size from 3×3 to 4×4 slightly reduces QA performance but leads to significant captioning quality degradation. This is because video benchmarks are relatively high-level and don’t require understanding small details, so reducing pool size doesn’t harm much. This illustrates the importance of tracking captioning metrics alongside other benchmarks, as it requires more fine-grained video understanding. Finally, caption models based solely on human transcriptions (V) produce worse results than those including frame-level captions (VF), but training on mixtures of these captions doesn’t yield better results.
Conclusion
Molmo2, a suite of open-source vision-language models, achieves significant advances in video understanding and grounding capabilities. Molmo2 demonstrates exceptional grounding capabilities across single-image, multi-image, and video tasks, surpassing existing open-source models across multiple benchmarks and even exceeding proprietary models in certain tasks.
Molmo2’s key contribution lies in its unique dataset collection, including 7 new video datasets and 2 multi-image datasets. These datasets were collected without reliance on closed VLMs, providing valuable resources to the open-source community. Particularly noteworthy, these datasets cover highly detailed video captioning, free-form video QA, novel object tracking with complex queries, and innovative video pointing tasks.
In training, Molmo2 employs efficient packing and message tree encoding schemes, introducing bidirectional attention on visual tokens and a novel token weighting strategy, all significantly enhancing model performance. Experimental results show that Molmo2’s 8B model excels in short video, counting, and captioning tasks while remaining competitive in long video tasks. Molmo2’s performance in video grounding is particularly outstanding, significantly outperforming existing open-source models like Qwen3-VL and surpassing proprietary models like Gemini 3 Pro in tasks such as video pointing and tracking.
This work also provides detailed discussion of Molmo2’s architecture and training process, conducting comprehensive ablation experiments to explore how different components impact model performance. Experimental results validate the importance of bidirectional attention, token weighting, and temporal information for enhancing model performance.
Despite Molmo2’s significant achievements, the work also notes some limitations, such as slightly lower performance on OCR-intensive tasks compared to certain open-weight models, and the inherent complexity of video grounding tasks and limitations in long video grounding support. Future work plans to further improve Molmo2 by collecting more high-count examples, optimizing point tracking data generation processes, and exploring more effective long video processing strategies.
The release of Molmo2 and its high-quality open-source datasets undoubtedly injects new vitality into vision-language model research and development, promising to propel the field to new heights.