ByteDance has unveiled InfinityStar, a groundbreaking AI video generation framework that reduces the time required to create a 5-second 720p video from over 30 minutes to just 58 seconds. Built upon a unified architecture, InfinityStar supports diverse visual generation tasks — including image generation, text to video, image to video, and video continuation — within a single framework.

This launch signals a new era where the core architecture of visual generation is shifting decisively from the U-Net family to Transformer-based systems.
Table of Contents
From Diffusion to Transformer: The Evolution of Visual Generation
The story of AI visual generation has seen two main evolutionary routes — diffusion models and autoregressive models.
- 2022 – Stable Diffusion introduced a new paradigm for image generation, and its 1.5 version still dominates consumer markets.
- 2023 – DiT (Diffusion Transformer) architecture marked a transition, replacing U-Net with Transformers, enabling scaling laws for larger models.
- 2024 – OpenAI’s Sora demonstrated this scaling law effect in video generation, cutting videos into “spacetime patches” to produce minute-long videos with realistic motion.
Meanwhile, autoregressive models were quietly catching up.
- 2023 – VideoPoet explored applying language model principles to video generation but faced limitations in quality and efficiency.
- 2024 – VAR (Visual Autoregressive Modeling) introduced next-scale prediction, replacing pixel-by-pixel prediction with feature-map-level prediction — greatly boosting image quality.
- Late 2024 – Infinity Model took it further with bit-level modeling, expanding its token vocabulary to an incredible 2⁶⁴ entries, achieving image quality rivaling diffusion models while being 8× faster.
Yet both paths had trade-offs — diffusion models were slow and hard to extend for video continuation, while autoregressive models struggled with visual fidelity and inference latency.
InfinityStar breaks this trade-off.
Why InfinityStar Matters: Quality, Speed, and Scalability in One
InfinityStar achieves industrial-grade video generation quality while maintaining lightning-fast efficiency. Its foundation is a new architectural principle: the Spacetime Pyramid Model.
Spacetime Pyramid Model: Decoupling Space and Time
Unlike traditional models that treat video as a uniform 3D block, InfinityStar separates appearance (static elements) from motion (dynamic changes).
Spacetime Pyramid Model
Each video is divided into fixed-length clips (e.g., 5 seconds or 80 frames at 16 fps).
- The first clip encodes static appearance cues — layout, texture, and color.
- Subsequent clips encode motion dynamics, represented through multi-scale pyramids of progressively higher resolution.
This leads to two cascades:
- Scale Cascade: generates finer details within each clip.
- Temporal Cascade: generates clips sequentially over time.
This spatiotemporal decoupling allows InfinityStar to extend videos theoretically without length limits, maintaining consistency across time while keeping memory usage stable.
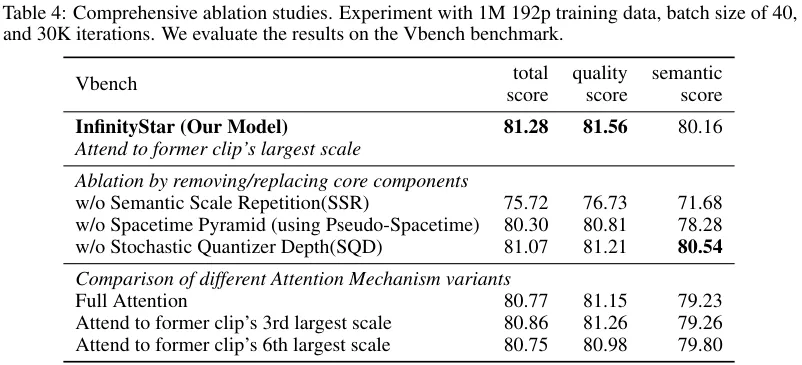
In benchmark tests, InfinityStar’s architecture achieved a VBench score of 81.28, outperforming conventional coupled designs.
Knowledge Inheritance: Standing on the Shoulders of Giants
Training a video tokenizer is notoriously expensive, but InfinityStar introduces a powerful shortcut: Knowledge Inheritance.
Instead of training from scratch, it leverages a pre-trained Wan 2.1 VAE and inserts a binary spherical quantizer with dynamically allocated vocabularies — smaller for low-resolution scales and massive (2⁶⁴) for detailed scales.
Results:
- PSNR: 33.37 dB
- SSIM: 0.94
- LPIPS: 0.065
compared to 30.04 dB / 0.90 / 0.124 from training without inheritance — a major leap.
This strategy cuts training cost by 3×, achieving faster convergence and higher reconstruction fidelity.
To address token imbalance across scales, InfinityStar also introduces Stochastic Quantizer Depth (SQD) — randomly dropping late-stage scales during training, forcing early scales to encode essential semantics. This improves structural clarity and consistency.
Making Transformers Understand Space and Time
InfinityStar enhances its Transformer backbone with two new attention mechanisms:
1. Semantic Scale Repetition (SSR)
Early scales encode global semantics (layout, subject position, motion path). By re-predicting these scales multiple times, InfinityStar improves semantic consistency with only 5% additional computation. Removing SSR causes VBench scores to drop from 81.28 → 75.72, confirming its impact.
ssr result
2. Spacetime Sparse Attention (SSA)
To reduce memory overhead, SSA lets each new clip attend only to its own previous scales and the final scale of the previous clip — reducing complexity from O(N²) to O(N).
This yields 1.5× speedup, lowering VRAM from 57 GB to 40 GB while improving stability and consistency.
Performance: Redefining AI Video Generation Speed
InfinityStar’s performance results are extraordinary:
| Task | Metric | InfinityStar | Competing Model |
| T2I (GenEval) | Semantic Accuracy | 0.79 | NextStep-1 (0.73), FLUX-dev (0.67) |
| DPG (T2I) | Text Alignment | 86.55 | +3.09 ↑ over Infinity v1 |
| T2V (VBench) | Overall Score | 83.74 | HunyuanVideo (83.24), Wan 2.1 (84.70) |
In human evaluation, InfinityStar outperformed HunyuanVideo in:
- Text alignment (68% win rate)
- Visual quality (72%)
- Motion smoothness (65%)
- Temporal consistency (71%)
In image to video AI tasks, it maintained over 60% win rate across all criteria.
58 Seconds to Render a 720p Video
On a single NVIDIA A100 GPU, InfinityStar generates a 5-second, 720p video in only 58 seconds, compared to:
- Wan 2.1 (Diffusion): 1864 seconds (~31 minutes)
- Nova (Autoregressive): 354 seconds (~6 minutes)
That’s a 32× speedup over diffusion and 6× faster than autoregressive models, thanks to its 26-step inference process — each step predicting thousands of tokens in parallel.

InfinityStar-Interact: Toward Infinite-Length Interactive Generation
To support long-form and interactive AI video generation, ByteDance introduced InfinityStar-Interact, which uses 5-second sliding windows overlapping by 2.5 seconds.
A semantic-detail dual-branch conditioning mechanism keeps video identity and motion coherent while cutting interaction delay by 5×.
Even after 10 interaction rounds, identity drift remains below 2 pixels of deviation, a remarkable feat for autoregressive video synthesis.
Current Challenges and Future Directions
While InfinityStar marks a monumental leap, challenges remain:
- Slight quality drop (~1.5 dB PSNR) in high-motion scenes.
- Cumulative drift in ultra-long interactions (~12% decline after 10 rounds).
- Parameter scale (8B) still leaves room for scaling-up improvements.
Next-Gen AI Video Generation with Autoregressive Technology
MAGI-1 and Gaga AI Lead the Future of Frame-to-Frame Intelligence
Autoregressive video generation has become one of the most exciting breakthroughs in AI video modeling. Unlike diffusion-only systems that render entire sequences at once, autoregressive models like MAGI-1 and Gaga AI generate each frame based on the previous one—resulting in unprecedented temporal coherence, scene continuity, and realism.

MAGI-1: Autoregressive Video Generation at Scale
MAGI-1 is a large-scale autoregressive world model designed to generate videos chunk-by-chunk, maintaining consistency across time while supporting real-time streaming generation. Developed by SandAI, MAGI-1 is built on a Transformer-based VAE architecture with 8× spatial and 4× temporal compression, achieving fast decoding and high-quality reconstruction.
Key Highlights:
- Autoregressive Denoising Algorithm: Generates 24-frame chunks sequentially, ensuring smooth transitions and allowing concurrent processing of multiple chunks for faster video synthesis.
- Diffusion Transformer Architecture: Introduces Block-Causal Attention, Parallel Attention Block, QK-Norm, GQA, and Softcap Modulation for large-scale stability and performance.
- Shortcut Distillation: Enables flexible inference budgets and efficient generation with minimal fidelity loss.
- Controllable Generation: Supports chunk-wise prompting, enabling fine-grained control, long-horizon storytelling, and seamless scene transitions.
Performance:
MAGI-1 achieves state-of-the-art results among open-source video models like Wan-2.1 and HunyuanVideo, and even challenges commercial systems such as Kling and Sora. It excels in instruction following, motion realism, and physical consistency, making it a benchmark for autoregressive I2V (image-to-video) and T2V (text-to-video) tasks.
Latest MAGI-1 Updates:
- May 30, 2025: ComfyUI support added – MAGI-1 custom nodes now available for workflow integration.
- May 26, 2025: MAGI-1 4.5B Distill and Distill+Quant models released.
- May 14, 2025: Dify DSL for prompt enhancement introduced.
- Apr 30, 2025: MAGI-1 4.5B base model launched.
- Apr 21, 2025: MAGI-1 official release with full weights and inference code.
Supported Models (Model Zoo):
| Model | Type | Recommended Hardware |
| MAGI-1-24B | Full model | H100/H800 × 8 |
| MAGI-1-24B-Distill | Distilled | H100/H800 × 8 |
| MAGI-1-24B-Distill+Quant | Quantized | H100/H800 × 4 or RTX 4090 × 8 |
| MAGI-1-4.5B | Compact | RTX 4090 × 1 |
| MAGI-1-4.5B-Distill+Quant | Optimized | RTX 4090 × 1 (≥12GB VRAM) |
Developers can run MAGI-1 easily with Docker or from source code, and it supports Text-to-Video, Image-to-Video, and Video-to-Video modes.
For prompt enhancement, MAGI-1 integrates with Dify DSL, enabling better creative control and refined instruction parsing for natural, cinematic results.
Technical Report: MAGI-1: Autoregressive Video Generation at Scale (arXiv, 2025)
Gaga AI: Democratizing Autoregressive Video Creation
While MAGI-1 demonstrates the power of autoregressive video modeling at research scale, Gaga AI brings this innovation to creators, marketers, and digital storytellers through an intuitive, no-code platform.
Powered by Gaga-1, its proprietary autoregressive video model, Gaga AI enables:
- Image-to-Video AI: Animate any still photo with natural facial motion.
- AI Voice Clone + Lip Sync AI: Generate perfectly matched dialogue and expressions.
- AI Avatars: Build digital presenters that speak, move, and emote realistically.
- Text-to-Video Generation: Convert scripts or ideas into cinematic clips.
- Autoregressive Precision: Frame-aware synthesis ensures lifelike continuity and zero frame flicker.
With Autoregressive tech, Gaga AI delivers what diffusion-only systems can’t—human-like storytelling flow, coordinated emotion, and true audiovisual coherence.
In essence, MAGI-1 sets the technical foundation for large-scale autoregressive modeling, while Gaga AI makes the same innovation accessible to creators everywhere, merging AI research excellence with real-world creativity.
Conclusion: InfinityStar & Gaga AI Bring the AI Video Era into Real Time
The AI video landscape is rapidly evolving from diffusion-based synthesis to fully autoregressive generation. Research breakthroughs like MAGI-1 have proven the power of chunk-wise temporal prediction, enabling stable, instruction-following video creation with cinematic coherence. Meanwhile, Gaga AI is translating these innovations into a creator-friendly platform — bringing autoregressive performance, natural lip-sync, and expressive AI avatars to everyday storytellers.
Now, with ByteDance’s InfinityStar, the autoregressive revolution reaches real-time speed and industrial-grade precision. By combining five foundational innovations — Spacetime Pyramid Modeling, Knowledge Inheritance Tokenizer, Stochastic Quantizer Depth, Semantic Scale Repetition, and Spacetime Sparse Attention — InfinityStar becomes the first discrete autoregressive framework capable of generating 720p videos in under one minute.
Together, MAGI-1, Gaga AI, and InfinityStar define the new frontier of AI video generation — where research-grade intelligence, creator accessibility, and real-time performance converge. The next chapter of video creation is no longer just AI-assisted; it’s AI-driven, autoregressive, and truly alive.
References
- InfinityStar Paper (arXiv)
- InfinityStar GitHub
- InfinityStar Model on Hugging Face
- ByteDance Open Source Discord