Key Takeaways
- Gemini 3 Flash is Google’s speed-optimized frontier model that delivers Gemini 3 Pro-grade reasoning at 3x faster performance and significantly lower cost
- Pricing: $0.50 per 1M input tokens and $3.00 per 1M output tokens — more cost-effective than competitors for most workloads due to 30% fewer tokens used
- Benchmark performance rivals larger models: 90.4% on GPQA Diamond, 81.2% on MMMU Pro, 78% on SWE-bench Verified
- Available globally now as the default model in Gemini app, AI Mode in Search, Gemini API, Vertex AI, and Google AI Studio
- Best for: Agentic workflows, production coding, real-time multimodal analysis, and high-frequency interactive applications

Table of Contents
What Is Gemini 3 Flash?
Gemini 3 Flash is Google’s latest high-speed AI model that combines frontier-level intelligence with exceptional efficiency. Released as part of the Gemini 3 model family, it delivers Gemini 3 Pro-grade reasoning capabilities while operating at significantly faster speeds and lower costs than its predecessor, Gemini 2.5 Pro.
The model processes over 1 trillion tokens daily across Google’s API infrastructure and serves as the default model for millions of users worldwide in the Gemini app. Unlike traditional “lightweight” models that sacrifice intelligence for speed, Gemini 3 Flash maintains frontier performance on complex reasoning tasks while achieving 3x faster response times.
Core Capabilities
Gemini 3 Flash excels across five key areas:
1. PhD-level reasoning on complex multi-step problems
2. Multimodal understanding across text, images, video, and audio
3. Production-grade coding with agentic workflow optimization
4. Real-time visual analysis for interactive applications
5. Token efficiency using 30% fewer tokens than comparable models for equivalent tasks
Gemini 3 Flash Benchmarks: How It Performs Against Competitors
Academic and Reasoning Benchmarks
Gemini 3 Flash demonstrates frontier-level performance across industry-standard benchmarks:
| Benchmark | Gemini 3 Flash | Gemini 3 Pro | Gemini 2.5 Pro | GPT-5.2 | Purpose |
| GPQA Diamond | 90.4% | ~92% | ~85% | ~89% | PhD-level science questions |
| Humanity’s Last Exam | 33.7% | 37.5% | ~28% | 34.5% | Cross-domain expertise (no tools) |
| MMMU Pro | 81.2% | 81.2% | ~75% | ~79% | Multimodal understanding & reasoning |
| SWE-bench Verified | 78% | 75% | ~68% | 82% | Real-world coding agent capabilities |
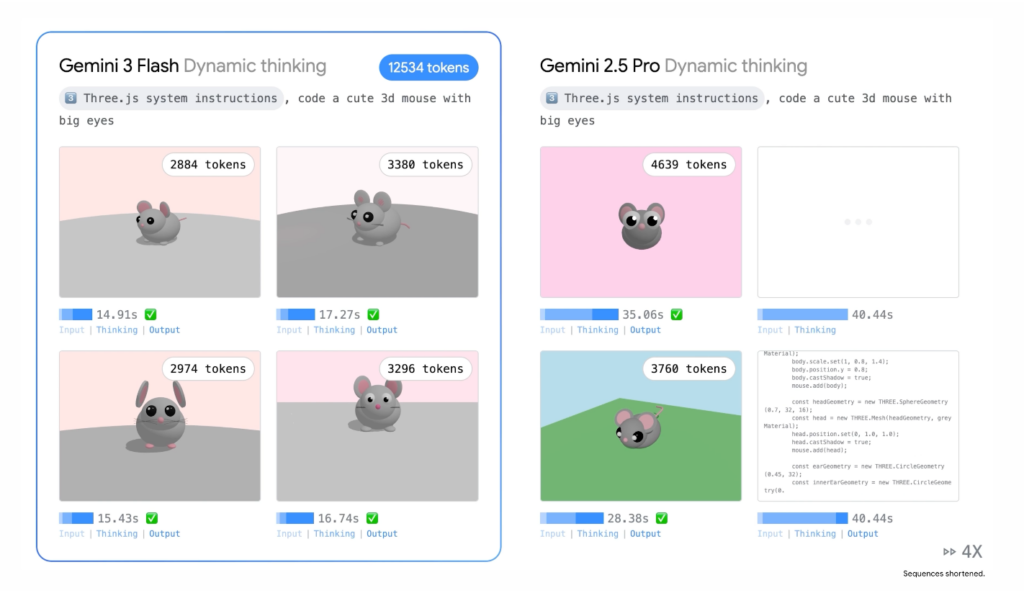
Key Finding: Gemini 3 Flash achieves performance comparable to or exceeding larger frontier models like Gemini 3 Pro on multiple benchmarks, particularly excelling in multimodal reasoning (MMMU Pro) and coding tasks (SWE-bench Verified).
Speed and Efficiency Metrics
Based on Artificial Analysis benchmarking and Google’s internal metrics:
- 3x faster than Gemini 2.5 Pro at equivalent quality levels
- 30% fewer tokens used on average for typical tasks compared to 2.5 Pro
- Higher thinking modulation — adjusts computational effort based on query complexity
- Sub-second latency for most queries in production environments
Gemini 3 Flash Pricing: API Cost Breakdown
Standard Pricing Structure
Current Gemini 3 Flash API pricing:
- Input tokens: $0.50 per 1 million tokens
- Output tokens: $3.00 per 1 million tokens
- Audio input: $1.00 per 1 million tokens
Cost Comparison vs Other Models
| Model | Input (per 1M) | Output (per 1M) | Speed Multiplier | Token Efficiency |
| Gemini 3 Flash | $0.50 | $3.00 | 3x (baseline) | 30% fewer tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1x | Baseline |
| Gemini 2.5 Pro | $1.25 | $5.00 | 0.33x | Baseline |
| Gemini 3 Pro | $2.50 | $10.00 | 1x | Similar to 3 Flash |
Real-World Cost Analysis:
For a typical task requiring 100,000 input tokens and 20,000 output tokens:
- Gemini 3 Flash: $0.05 + $0.06 = $0.11 total
- Gemini 2.5 Pro: Would require ~30% more tokens: $0.16 + $0.13 = $0.29 total
Despite slightly higher per-token pricing than Gemini 2.5 Flash, Gemini 3 Flash often costs less in practice due to superior token efficiency and reduced need for retries or corrections.
Gemini 3 Flash vs Gemini 3 Pro: Which Model Should You Choose?
Direct Comparison
Choose Gemini 3 Flash when you need:
- High-frequency API calls with budget constraints
- Real-time or near-real-time responses (gaming, chat, live analysis)
- Agentic workflows with multiple iterative steps
- Production systems processing large volumes
- Rapid prototyping and development cycles
Choose Gemini 3 Pro when you need:
- Maximum accuracy on the most complex reasoning tasks
- Deep research requiring extensive context processing
- Tasks where latency is not a primary concern
- Highest possible performance on mathematical proofs
- Enterprise applications with premium quality requirements
Performance Comparison Matrix
| Dimension | Gemini 3 Flash | Gemini 3 Pro | Winner |
| Speed | 3x faster | Baseline | Flash |
| Cost | $0.50/$3.00 | $2.50/$10.00 | Flash |
| Reasoning (GPQA) | 90.4% | ~92% | Pro (marginal) |
| Coding (SWE-bench) | 78% | 75% | Flash |
| Multimodal (MMMU Pro) | 81.2% | 81.2% | Tie |
| Token Efficiency | High | High | Tie |
| Best Use Case | Agentic/Production | Deep Research | Context-dependent |
Bottom Line: Gemini 3 Flash outperforms Gemini 3 Pro on coding benchmarks while matching it on multimodal tasks, making it the superior choice for 80% of production use cases. Reserve Gemini 3 Pro for tasks requiring absolute maximum reasoning capability.
How to Access Gemini 3 Flash: Platform Availability
For Developers
1. Gemini API (Google AI Studio)
- Status: Available now in preview
- Access: Visit ai.google.dev
- Implementation: RESTful API with SDKs for Python, Node.js, Go, Kotlin
- Rate limits: 1500 requests per minute (may vary by tier)
Quick start example:
import google.generativeai as genai
genai.configure(api_key=’YOUR_API_KEY’)
model = genai.GenerativeModel(‘gemini-3-flash’)
response = model.generate_content(‘Explain quantum computing’)
2. Vertex AI (Enterprise)
- Status: Generally available
- Access: Through Google Cloud Console
- Features: Enhanced security, SLA guarantees, dedicated support
- Pricing: Same base rates plus Google Cloud infrastructure costs
3. Google Antigravity
- Status: Preview access
- Purpose: Agentic development platform for production-ready applications
- Integration: Built-in Gemini 3 Flash support for rapid iteration
4. Additional Developer Tools
- Gemini CLI: Command-line interface for terminal-based workflows
- Android Studio: Native integration for mobile development
- Third-party platforms: Available through OpenRouter and other aggregators
For End Users
1. Gemini App (Free Access)
- Default model globally — replaced Gemini 2.5 Flash
- Available on: Web, iOS, Android
- Cost: Free for all users
- Model picker: Can switch to Gemini 3 Pro for advanced tasks
2. AI Mode in Search
- Rolling out globally as default
- Provides visually enriched, multi-step answers
- Combines web search with frontier reasoning
- Free for all Google Search users
3. Gemini Enterprise
- Available to enterprise customers via Workspace
- Enhanced privacy and data governance controls
- Custom deployment options
Top Use Cases: What Gemini 3 Flash Does Best
1. Agentic Coding Workflows
Gemini 3 Flash achieves 78% on SWE-bench Verified, making it ideal for:
- Multi-step code generation with iterative refinement
- Bug detection and automated fixes in production codebases
- Code review and security analysis at scale
- API integration and testing with rapid feedback loops
Example workflow: Companies like JetBrains and Cursor use Gemini 3 Flash to power AI pair programming features, where low latency enables real-time suggestions as developers type.
2. Real-Time Multimodal Analysis
With sub-second response times, Gemini 3 Flash enables:
- Live video analysis — analyze golf swings, workout form, or presentation delivery
- Audio transcription and analysis — identify knowledge gaps, generate quizzes from lectures
- Visual Q&A — answer questions about images, diagrams, or screenshots in conversational applications
- Drawing recognition — predict what users are sketching in real-time for design tools
Example implementation: Educational apps can upload a 2-minute lecture recording and receive personalized quiz questions with detailed explanations in under 5 seconds.
3. Production Data Processing
The 30% token efficiency advantage makes Gemini 3 Flash cost-effective for:
- Large-scale document analysis — extract structured data from invoices, contracts, forms
- Content moderation — classify and flag inappropriate content across platforms
- Sentiment analysis — process customer feedback at scale
- Automated reporting — generate summaries from business data
4. Interactive User Applications
Low latency combined with strong reasoning enables:
- In-game AI assistants — provide contextual help based on player actions
- Chatbots and virtual agents — handle customer service with nuanced understanding
- A/B testing automation — generate and test design variations in real-time
- Voice-to-app prototyping — convert unstructured voice descriptions into functional apps
Real example from Google’s demo: A user describes an app idea via voice, and Gemini 3 Flash generates a working prototype in under 2 minutes.
5. Enterprise Knowledge Management
Companies like Bridgewater Associates and Harvey use Gemini 3 Flash for:
- Legal document analysis — extract key clauses and obligations at scale
- Financial research — synthesize information from multiple reports
- Internal knowledge search — provide accurate answers from company documentation
- Automated workflow orchestration — coordinate multi-step business processes
How to Optimize Your Applications for Gemini 3 Flash
1. Leverage Adaptive Thinking
Gemini 3 Flash modulates its computational effort based on query complexity. Structure prompts to help the model calibrate appropriately:
Instead of: “Solve this problem: [complex multi-step math problem]”
Try: “This is a multi-step calculus problem requiring integration by parts. Work through it systematically: [problem]”
2. Maximize Token Efficiency
Take advantage of the 30% token reduction:
- Batch related queries instead of making multiple API calls
- Use structured output formats (JSON, markdown tables) for cleaner responses
- Provide clear context upfront rather than iterative clarification
- Set appropriate max_tokens limits to avoid over-generation
3. Design for Multimodal Workflows
Gemini 3 Flash excels when combining modalities:
- Pair images with text for visual reasoning tasks
- Include audio transcripts with context for richer analysis
- Chain video → text → code pipelines for video-to-app workflows
- Use PDFs with specific page references to target extraction
4. Implement Agentic Patterns
For coding and problem-solving tasks:
- Break complex tasks into subtasks the model can tackle iteratively
- Provide function definitions for tool use and API integration
- Enable streaming responses for better user experience
- Implement retry logic for edge cases (though less needed than 2.5 models)
5. Monitor and Optimize Costs
- Track token usage across different prompt patterns
- Compare Flash vs Pro on representative sample queries
- Implement caching for repeated queries or context
- Use Flash for initial drafts, then Pro for final refinement if needed
Gemini 3 Flash Release Timeline and Rollout
Release Phases
Phase 1: Developer Preview (Current)
- Date: December 2024
- Platforms: Gemini API, Google AI Studio, Vertex AI
- Access: Open to all developers with API keys
- Status: Preview with production-grade stability
Phase 2: Consumer Rollout (Current)
- Date: December 2024 – January 2025
- Platforms: Gemini app (web, iOS, Android), AI Mode in Search
- Access: Free for all users globally
- Default model: Replaced Gemini 2.5 Flash
Phase 3: Enterprise Availability (Current)
- Date: December 2024 onward
- Platforms: Gemini Enterprise, Vertex AI with SLAs
- Access: Via Google Cloud and Workspace contracts
- Adoption: Companies like JetBrains, Figma, Bridgewater already deployed
Gemini 3 Family Context
Gemini 3 Flash is the third model in the Gemini 3 family:
1. Gemini 3 Pro (November 2024) — Flagship reasoning model
2. Gemini 3 Deep Think (November 2024) — Extended reasoning mode
3. Gemini 3 Flash (December 2024) — Speed-optimized frontier model
Since the Gemini 3 family launch, Google has processed over 1 trillion tokens per day across its API infrastructure, indicating massive developer adoption.
Integration Examples: Gemini 3 Flash in Action
Example 1: Video Analysis API
import google.generativeai as genai
from pathlib import Path
genai.configure(api_key=’YOUR_API_KEY’)
model = genai.GenerativeModel(‘gemini-3-flash’)
# Upload video file
video_file = genai.upload_file(path=Path(‘golf_swing.mp4’))
# Analyze with specific prompt
response = model.generate_content([
video_file,
“Analyze this golf swing and provide 3 specific improvements with timestamps.”
])
print(response.text)
# Returns detailed analysis in under 3 seconds
Example 2: Document Data Extraction
# Extract structured data from invoice
response = model.generate_content([
invoice_image,
“””Extract the following fields as JSON:
– invoice_number
– date
– total_amount
– line_items (array with description and amount)
“””
])
import json
invoice_data = json.loads(response.text)
Example 3: Multi-Turn Coding Agent
# Iterative development workflow
context = []
# Step 1: Generate initial code
response = model.generate_content(“Create a Python function to validate email addresses”)
context.append({“role”: “model”, “parts”: [response.text]})
# Step 2: Refine with tests
context.append({“role”: “user”, “parts”: [“Add unit tests for edge cases”]})
response = model.generate_content(context)
# Step 3: Optimize
context.append({“role”: “model”, “parts”: [response.text]})
context.append({“role”: “user”, “parts”: [“Optimize for performance”]})
final_response = model.generate_content(context)
Gemini 3 Flash vs Competitors: Market Position
vs OpenAI GPT-5.2
| Aspect | Gemini 3 Flash | GPT-5.2 |
| Speed | 3x faster than 2.5 Pro | Standard latency |
| Coding (SWE-bench) | 78% | 82% |
| Reasoning (HLE) | 33.7% | 34.5% |
| Cost | $0.50/$3.00 | $2.50/$7.50 (estimated) |
| Multimodal | Native support | Native support |
| Availability | Global, free tier | API access, subscription |
Verdict: Gemini 3 Flash trades marginal reasoning accuracy for significantly better speed and cost-efficiency, making it superior for production workloads.
vs Claude 3.5 Sonnet
- Strength of Gemini 3 Flash: Faster inference, lower cost, stronger multimodal
- Strength of Claude 3.5 Sonnet: Longer context windows (200K), nuanced writing
- Use case separation: Flash for speed-critical apps, Claude for long-document analysis
Market Dynamics
Google’s aggressive pricing and performance have intensified AI model competition:
- OpenAI’s response: Released GPT-5.2 shortly after Gemini 3 Flash announcement
- Google’s traffic growth: Gemini app usage increased significantly post-Gemini 3 launch
- Enterprise adoption: Companies increasingly using multiple models based on task requirements
Bonus: Enhancing Gemini 3 Flash Workflows with Gaga AI Video Generator
For developers building multimodal applications, Gaga AI video generator complements Gemini 3 Flash’s analysis capabilities:
Integration pattern:
1. Use Gemini 3 Flash to analyze user requirements or existing video content
2. Generate text prompts or storyboards based on the analysis
3. Feed prompts to Gaga AI to create video content
4. Use Gemini 3 Flash again to validate or iterate on generated videos
Example use case: An e-learning platform uses Gemini 3 Flash to analyze course content, identifies gaps requiring visual explanation, generates video prompts, creates videos with Gaga AI, then validates the videos match learning objectives — all in an automated pipeline.
Frequently Asked Questions (FAQ)
What is Gemini 3 Flash used for?
Gemini 3 Flash is designed for production applications requiring both frontier-level intelligence and fast response times. Primary use cases include agentic coding workflows, real-time multimodal analysis (video, audio, images), interactive chatbots, automated data extraction, and high-volume content processing. Its combination of speed and reasoning makes it ideal for developers building user-facing AI features where latency directly impacts experience.
How much does Gemini 3 Flash cost?
Gemini 3 Flash costs $0.50 per 1 million input tokens and $3.00 per 1 million output tokens via the Gemini API. Audio input is priced at $1.00 per 1 million tokens. For end users, Gemini 3 Flash is available for free in the Gemini app and AI Mode in Search. The model uses 30% fewer tokens on average compared to Gemini 2.5 Pro, making it more cost-effective than per-token pricing suggests.
Is Gemini 3 Flash better than Gemini 3 Pro?
Gemini 3 Flash outperforms Gemini 3 Pro on coding tasks (78% vs 75% on SWE-bench Verified) while matching it on multimodal reasoning (both score 81.2% on MMMU Pro). Gemini 3 Pro has a slight edge on pure reasoning tasks like GPQA Diamond (92% vs 90.4%). For most production use cases, Gemini 3 Flash is the better choice due to 3x faster speed and 5x lower cost with comparable intelligence. Choose Pro only for tasks requiring absolute maximum reasoning accuracy.
How fast is Gemini 3 Flash compared to other models?
Gemini 3 Flash is 3x faster than Gemini 2.5 Pro according to Artificial Analysis benchmarks, typically delivering responses in under 2 seconds for standard queries. This makes it one of the fastest frontier-class models available. The speed advantage comes from architectural optimizations that don’t sacrifice reasoning capability, enabling real-time applications like live video analysis and interactive coding assistants.
Can I use Gemini 3 Flash for free?
Yes. Gemini 3 Flash is available for free to all users worldwide through the Gemini app (web, iOS, Android) and AI Mode in Google Search. It serves as the default model for free-tier users, replacing Gemini 2.5 Flash. Developers can also access free quotas through Google AI Studio for testing and prototyping before scaling to paid API usage.
What are the benchmark scores for Gemini 3 Flash?
Gemini 3 Flash achieves the following benchmark scores: GPQA Diamond 90.4% (PhD-level science), Humanity’s Last Exam 33.7% (cross-domain expertise), MMMU Pro 81.2% (multimodal reasoning – highest among competitors), and SWE-bench Verified 78% (coding agent capabilities). These scores demonstrate frontier-level performance comparable to much larger and more expensive models.
When was Gemini 3 Flash released?
Gemini 3 Flash was released in December 2024 as the third model in the Gemini 3 family, following Gemini 3 Pro and Gemini 3 Deep Think (both released November 2024). The model launched simultaneously across multiple platforms: Gemini API, Google AI Studio, Vertex AI, the Gemini consumer app, and AI Mode in Search, with global rollout ongoing through January 2025.
Which companies are using Gemini 3 Flash?
Major companies using Gemini 3 Flash include JetBrains (AI-powered coding tools), Figma (design automation), Cursor (AI code editor), Harvey (legal AI), Bridgewater Associates (financial analysis), and Latitude (interactive experiences). These enterprises leverage Gemini 3 Flash’s combination of speed, reasoning capability, and cost-efficiency for production-scale AI applications.
How do I access Gemini 3 Flash API?
Access Gemini 3 Flash API through Google AI Studio at ai.google.dev (for developers) or Vertex AI via Google Cloud Console (for enterprises). Obtain an API key from either platform, then use Google’s GenerativeAI SDKs for Python, Node.js, Go, or Kotlin. The model identifier is ‘gemini-3-flash’. Preview access is currently available with production-grade stability and standard rate limits of 1500 requests per minute.
Does Gemini 3 Flash support multimodal inputs?
Yes. Gemini 3 Flash natively supports text, images (JPG, PNG, WebP), video (MP4, MOV), audio (MP3, WAV), and PDF documents as inputs. The model achieves state-of-the-art performance on MMMU Pro (81.2%), demonstrating advanced multimodal reasoning. You can combine multiple modalities in a single query, such as uploading a video and asking text-based questions about its content, with responses generated in under 3 seconds.
What’s the difference between Gemini 3 Flash and Gemini 2.5 Flash?
Gemini 3 Flash significantly outperforms Gemini 2.5 Flash on all major benchmarks while being 3x faster. Key improvements: 90.4% vs ~85% on GPQA Diamond, 33.7% vs 11% on Humanity’s Last Exam, and 81.2% vs ~70% on MMMU Pro. Gemini 3 Flash also uses 30% fewer tokens for equivalent tasks. The pricing is slightly higher per token ($0.50 vs $0.30 input) but overall cost is often lower due to efficiency gains. Gemini 3 Flash has replaced 2.5 Flash as the default model globally.
Can Gemini 3 Flash write and debug code?
Yes. Gemini 3 Flash achieves 78% on SWE-bench Verified, a benchmark that tests real-world coding agent capabilities. This score actually exceeds Gemini 3 Pro (75%) and rivals GPT-5.2 (82%), making it one of the strongest coding models available. The model excels at iterative development, bug detection, code review, test generation, and multi-file projects. Its low latency makes it ideal for real-time coding assistants and agentic workflows.
Is Gemini 3 Flash available in Google Search?
Yes. Gemini 3 Flash is rolling out as the default model for AI Mode in Google Search globally. This integration provides visually rich, multi-step answers that combine web search results with Gemini 3 Flash’s reasoning capabilities. The feature pulls real-time information from across the web while offering the speed and intelligence of Gemini 3 Flash, making it effective for complex queries requiring research and immediate action.
How many tokens does Gemini 3 Flash use compared to other models?
Gemini 3 Flash uses approximately 30% fewer tokens than Gemini 2.5 Pro for typical tasks due to more efficient reasoning and response generation. This efficiency gain means that despite slightly higher per-token costs ($0.50 vs $0.30 for 2.5 Flash), the total cost per task is often lower. The model adaptively modulates its computational effort based on query complexity, using more tokens for difficult problems and fewer for straightforward tasks.
What is the context window for Gemini 3 Flash?
While Google has not publicly specified the exact context window size for Gemini 3 Flash, Gemini 3 family models support large context windows consistent with other frontier models (typically 128K-200K tokens). The model efficiently handles long documents, extended conversations, and multimodal inputs including lengthy videos. For specific context requirements, consult Google’s official documentation at ai.google.dev or contact enterprise support for Vertex AI deployments.
Conclusion: Is Gemini 3 Flash Right for Your Use Case?
Gemini 3 Flash represents a paradigm shift in AI model design: you no longer need to choose between intelligence and efficiency. The model delivers frontier-level reasoning at speeds 3x faster than previous generation models, with cost savings that make advanced AI accessible for production-scale applications.
Choose Gemini 3 Flash if you:
- Build applications where latency directly impacts user experience
- Need to process high volumes of requests cost-effectively
- Develop agentic systems requiring iterative reasoning
- Work with multimodal content (video, audio, images) requiring real-time analysis
- Want frontier-class intelligence without enterprise-tier pricing
Consider alternatives if you:
- Have unlimited budget and latency is not a concern (→ Gemini 3 Pro)
- Need 200K+ context windows for extremely long documents (→ Claude models)
- Require absolute maximum accuracy on specialized reasoning tasks (→ Gemini 3 Deep Think)
With over 1 trillion tokens processed daily since the Gemini 3 launch and rapid enterprise adoption, Gemini 3 Flash has proven itself as a production-ready model that balances cutting-edge capabilities with practical deployment requirements. For most developers and businesses, it represents the optimal choice in the current AI landscape.
Get started: Visit ai.google.dev to access the Gemini API, or open the Gemini app to start using Gemini 3 Flash for free today.