Key Takeaways
- GPT-5.2 launched December 11, 2025 as OpenAI’s response to Google Gemini 3’s market dominance
- Three model variants available: Instant (speed), Thinking (complex reasoning), and Pro (maximum accuracy)
- Expert-level performance: Beats or ties industry professionals on 70.9% of knowledge work tasks across 44 occupations
- Pricing: $1.75/1M input tokens, $14/1M output tokens via API; $20/month for ChatGPT Plus subscribers
- Key improvements over GPT-5.1: 30% fewer errors, 80% accuracy on SWE-bench Verified, 100% on AIME 2025 math problems
- Best for: Professional coding, spreadsheet creation, presentations, long-context analysis, and multi-step workflows

What Is GPT-5.2?
GPT-5.2 is a series of advanced large language models (LLMs) developed by OpenAI that delivers state-of-the-art performance in sophisticated, economically valuable tasks such as financial modeling, code refactoring, deep document analysis, and complex, multi-step customer support workflows.
The model is released in three tiers for various use cases:
- GPT-5.2 Instant (API: gpt-5.2-chat-latest): A fast, capable workhorse for everyday information retrieval and conversational tasks, with clearer, upfront explanations.
- GPT-5.2 Thinking (API: gpt-5.2): Designed for deeper work, excelling at coding, long document summarization, and step-by-step logic/math problems.
- GPT-5.2 Pro (API: gpt-5.2-pro): The smartest and most trustworthy option for the most difficult questions and domains requiring the highest quality, such as graduate-level science and abstract reasoning.
Table of Contents
Performance Benchmarks: Why GPT-5.2 is an Intelligence Leap
Professional Knowledge Work (GDPval)
GPT-5.2 Thinking achieves expert-level performance on GDPval, OpenAI’s benchmark measuring well-specified knowledge work tasks across 44 occupations. The model wins or ties against top industry professionals in 70.9% of comparisons, producing outputs 11 times faster and at less than 1% of the cost of human experts.
GDPval Win Rate: GPT-5.2 Thinking beats or ties top industry professionals on 70.9% of knowledge work tasks (e.g., creating presentations, spreadsheets, reports), a massive increase from GPT-5’s 38.8%.
Investment Banking Tasks: Its average score on junior investment banking analyst spreadsheet modeling tasks increased by 9.3%, rising from 59.1% (GPT-5.1) to 68.4%.
Tasks evaluated include creating sales presentations, accounting spreadsheets, urgent care schedules, manufacturing diagrams, and short videos. One GDPval judge commented that outputs appeared to have been produced by a professional company with full staff.
Agentic Coding Capabilities (SWE-Bench)
SWE-Bench Pro Performance:
GPT-5.2 delivers state-of-the-art agentic coding performance, making it highly effective for end-to-end software engineering tasks.
- GPT-5.2 Thinking: 55.6%
- GPT-5.1 Thinking: 50.8%
- Gemini 3 Pro: 43.3%
GPT-5.2 achieved 80% on SWE-bench Verified, compared to GPT-5.1’s 76.3%. This rigorous evaluation tests real-world software engineering across Python and multiple programming languages, with GPT-5.2 demonstrating improved ability to debug production code, implement feature requests, refactor large codebases, and ship fixes end-to-end with reduced manual intervention.
Mathematical Reasoning
AIME 2025 (Competition Math, No Tools):
- GPT-5.2 Thinking: 100%
- GPT-5.1 Thinking: 94.0%
FrontierMath (Advanced Mathematics, Tier 1-3):
- GPT-5.2 Thinking: 40.3%
- GPT-5.1 Thinking: 31.0%
Abstract Reasoning Breakthrough
On ARC-AGI-2, GPT-5.2 Thinking scored 52.9%, dramatically surpassing GPT-5.1’s 17.6%. This abstract reasoning benchmark measures fluid intelligence and novel problem-solving abilities. GPT-5.2 Pro reached 54.2%, establishing new state-of-the-art performance for chain-of-thought models.
On ARC-AGI-1, GPT-5.2 Pro achieved 90.5%, becoming the first model to cross the 90% threshold while reducing costs by approximately 390 times compared to o3-preview.
Scientific Knowledge
GPQA Diamond (Graduate-Level Science Questions):
- GPT-5.2 Pro: 93.2%
- GPT-5.2 Thinking: 92.4%
- GPT-5.1 Thinking: 88.1%
| Benchmark | GPT-5.2 Thinking Score | Improvement Context |
| GPQA Diamond (Graduate-level Science) | 92.4% | Highly accurate for complex, abstract scientific questions. |
| FrontierMath (Tier 1–3) (Expert Math) | 40.3% | New state-of-the-art, reflecting stronger logical and multi-step reasoning. |
| AIME 2025 (Competition Math) | 100.0% | Solves complex intermediate-level math competition problems perfectly. |
The Core Technical Upgrades of GPT-5.2
The substantial jump in general intelligence is powered by four key technical advancements that make the model “agent-ready.”
Long-Context Understanding
GPT-5.2 Thinking achieves near 100% accuracy on the 4-needle MRCR variant extending to 256,000 tokens, making it suitable for deep document analysis, contract review, research paper synthesis, transcript analysis, and multi-file project work while maintaining coherence across hundreds of thousands of tokens.
Enhanced Tool Calling and Agentic Workflow
GPT-5.2 Thinking achieves 98.7% accuracy on Tau2-bench Telecom, showcasing a major breakthrough in tool use reliability.
- The model can coordinate and manage complex, multi-turn, multi-step workflows (e.g., resolving a customer’s flight delay, rebooking, special seating, and compensation in a single interaction) with fewer breakdowns.
- This makes it ideal for building robust “mega-agents” that collapse fragile, multi-agent systems into a single, highly capable model.
Vision Capabilities
ScreenSpot-Pro (GUI Understanding):
- GPT-5.2 Thinking: 86.3%
- GPT-5.1 Thinking: 64.2%
The model demonstrates substantially improved ability to interpret dashboards, product screenshots, technical diagrams, and visual reports, cutting error rates roughly in half on chart reasoning and software interface understanding tasks.
Reduced Hallucination Rate (Factuality)
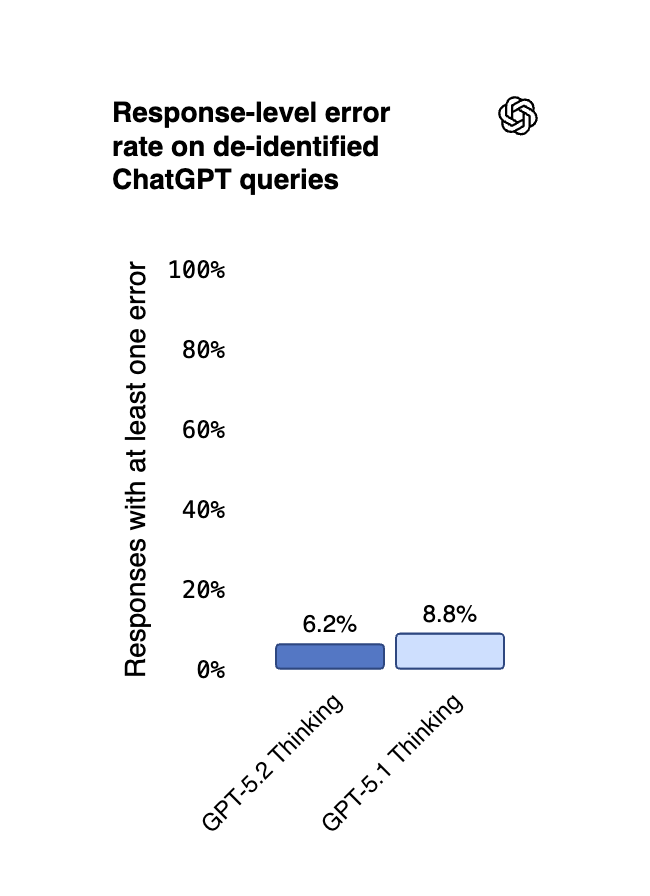
GPT-5.2 Thinking hallucinates 30% relatively less often than its predecessor.
- Responses with at least one error on a set of de-identified ChatGPT queries decreased from 8.8% to 6.2%. This makes the model more dependable for research and decision-support where accuracy is paramount.
GPT-5.2 vs GPT-5.1: What’s New?
| Feature Area | GPT-5.1 (Thinking) | GPT-5.2 (Thinking) | Key Improvement |
| Reasoning Engine | High | Higher | Substantially improved logical coherence for multi-step problems; resulting in more reliable outcomes for tasks requiring sustained analytical thinking. |
| Factuality / Error Rate | 8.8% (Responses with $\ge 1$ error) | 6.2% | 30% relative reduction in error rates. More dependable for professional research, analysis, and decision support. |
| Multimodal / Vision | Standard Image Comprehension | Enhanced Multimodal Understanding | Significant upgrade in visual comprehension, with accuracy on scientific figure interpretation (CharXiv Reasoning) increasing from 80.3% to 88.7%. Stronger spatial awareness. |
| Speed & Inference | Uniform Reasoning Mode | Adaptive Reasoning | The Instant model intelligently decides when to engage deeper thinking, providing more thorough answers without sacrificing speed on routine queries. |
| Memory & Personalization | Custom and Retentive | Adaptive and Predictive | Learns user style and preferences faster and retains them more reliably, enabling more contextually appropriate responses across long interactions. |
| Tool Access & Integration | Limited | Expanded | Seamless flow between coding, design, writing, and data analysis tasks, supporting richer, end-to-end agentic workflows without manual intervention. |
GPT-5.2 vs Gemini 3: Head-to-Head Comparison
Benchmark Showdown
Benchmark Showdown
GPT-5.2 Leads In:
- SWE-bench Verified: 80% vs 76.2%
- SWE-Bench Pro: 55.6% vs 43.3%
- AIME 2025 (no tools): 100% vs 95%
- ARC-AGI-1: 86.2% vs 75%
- GPQA Diamond: 92.4% vs 91.9%
Gemini 3 Leads In:
- MMMLU: 91.8% vs 89.6%
- Humanity’s Last Exam (no tools): 37.5% vs 34.5%
- Multimodal tasks and native video generation
- Broader product ecosystem integration
Pricing Comparison
gpt-5.2 pricing plans
API Costs:
- GPT-5.2: $1.75 per 1M input tokens, $14 per 1M output tokens
- Gemini 3: $2 per 1M input tokens, $12 per 1M output tokens
For a typical enterprise prompt with 20,000 input tokens and 5,000 output tokens:
- GPT-5.2: ~$0.105
- Gemini 3: ~$0.10
Subscription Plans:
- ChatGPT Plus: $20/month (GPT-5.2 access)
- ChatGPT Pro: $200/month (GPT-5.2 Pro access)
- Google AI Pro: $20/month (Gemini 3 access)
- Google AI Ultra: $249.99/month (includes cloud storage)
Architecture and Design Philosophy
OpenAI frames GPT-5.2 as a “knowledge work professional” upgrade focused on better spreadsheet construction, presentation generation, code synthesis, and tool use for multi-step projects with long context.
Gemini 3 is designed for expanse, serving as a natural bridge across text, vision, and media generation. Google tightly integrates Gemini 3 with its product ecosystem including Google Workspace, BigQuery, Maps, and NotebookLM, providing broader distribution advantages.
When to Choose GPT-5.2
- Building production-grade applications requiring precise tool use and structured outputs
- Coding tasks demanding iterative refinements and debugging
- Professional document creation (spreadsheets, presentations, reports)
- Multi-step analytical workflows with long context requirements
- Tasks where reasoning consistency matters more than multimodal breadth
When to Choose Gemini 3
- Heavy image and video-centric workflows
- Projects requiring native integration with Google Workspace and Cloud services
- Research tasks demanding extended context analysis
- Applications benefiting from unified text-vision-audio architecture
- Teams already invested in the Google ecosystem
How to Access GPT-5.2
ChatGPT Interface
GPT-5.2 began rolling out December 11, 2025 to paid ChatGPT subscribers, including:
- ChatGPT Plus ($20/month): Access to Instant and Thinking variants
- ChatGPT Pro ($200/month): Access to all variants including Pro
- ChatGPT Go, Business, and Enterprise: Full access with administrative controls
OpenAI deploys GPT-5.2 gradually to maintain service stability. If the new model isn’t immediately visible in your account, check back within 24-48 hours. GPT-5.1 remains available under legacy models for three months to allow comparison and transition time.
API Access
Developers can access GPT-5.2 immediately through OpenAI’s platform:
Model Identifiers:
- gpt-5.2: GPT-5.2 Thinking in Responses API and Chat Completions API
- gpt-5.2-chat-latest: GPT-5.2 Instant
- gpt-5.2-pro: GPT-5.2 Pro in Responses API
New Features for Developers:
- Fifth reasoning effort level (xhigh) for maximum quality
- Reasoning parameter control in GPT-5.2 Pro
- 90% discount on cached input tokens
- Responses /compact endpoint for extended context workflows
OpenAI has no current plans to deprecate GPT-5.1, GPT-5, or GPT-4.1 in the API, providing developers with model choice and backward compatibility.
GitHub Copilot Integration
GPT-5.2 became available in GitHub Copilot on December 11, 2025 for Pro, Pro+, Business, and Enterprise plans. Users can select the model from the Copilot picker in Visual Studio Code 1.104.1+, github.com, GitHub Mobile, and Copilot CLI.
Enterprise and Business administrators must enable GPT-5.2 in Copilot settings before users can access it. The rollout is gradual, with full availability expected within days.
Microsoft 365 Copilot
GPT-5.2 launched in Microsoft 365 Copilot on December 11, 2025, providing model choice across Microsoft’s productivity suite. Users can select GPT-5.2 from the model menu and leverage it for strategic analysis, meeting insights, and complex data synthesis tasks.
Other Emerging Models
Opus 4.5 (Anthropic): A close competitor, typically focusing on complex reasoning and safety/constitutional AI. It competes directly with GPT-5.2 Pro for high-stakes enterprise applications.
Sora 2 (Video): While not a direct LLM competitor, Sora 2’s advancement in video generation highlights the multi-modal race. GPT-5.2’s stronger vision model indicates OpenAI’s strategy to enhance LLM comprehension of visual inputs, which is complementary to video generation.
Gaga AI: An emerging rival often focused on specific regional or novel applications, but generally not yet competing at the generalized frontier intelligence level of GPT-5.2.
Real-World Applications and Use Cases
Professional Coding and Development
GPT-5.2 delivers measurable improvements for software engineers:
Interactive Coding: The model excels at front-end development and unconventional UI work, especially involving 3D elements. Early testers from Windsurf, Warp, JetBrains, Augment Code, and Charlie Labs reported state-of-the-art agentic coding performance.
Code Reviews and Bug Finding: Enhanced debugging capabilities help identify logical errors, security vulnerabilities, and performance bottlenecks with greater accuracy. The model can walk through complex codebases, suggest refactoring strategies, and implement fixes end-to-end.
Multi-Language Support: Unlike SWE-bench Verified (Python-only), GPT-5.2’s strong performance on SWE-Bench Pro demonstrates competence across four programming languages, making it suitable for polyglot development environments.
Business Intelligence and Data Analysis
Databricks, Hex, and Triple Whale found GPT-5.2 exceptional at agentic data science and document analysis tasks. The model’s long-context capabilities enable:
- Analyzing financial statements across multiple quarters
- Synthesizing insights from hundreds of customer feedback responses
- Building complex Excel models with proper formatting and citations
- Creating data visualizations with appropriate chart types and styling
On internal investment banking analyst tasks, GPT-5.2 Thinking’s average score rose from 59.1% to 68.4%, representing 9.3 percentage points of improvement in modeling accuracy.
Enterprise Knowledge Management
Notion, Box, Shopify, Harvey, and Zoom observed GPT-5.2 demonstrates state-of-the-art long-horizon reasoning and tool-calling performance. Organizations deploy GPT-5.2 for:
- Legal document review and contract analysis
- Compliance documentation and regulatory reporting
- Technical specification authoring
- Cross-departmental knowledge synthesis
The model’s reduced hallucination rate and improved factuality make it more reliable for decision support where accuracy carries financial or legal implications.
Customer Service and Support
On Tau2-bench Telecom, GPT-5.2 achieved 98.7% accuracy for tool use in customer support scenarios. The model can manage complete resolution workflows:
- Rebooking flights and coordinating connections
- Processing refunds and compensation claims
- Handling special assistance requests
- Coordinating across multiple backend systems
When presented with complex multi-step problems (delayed flights, missing baggage, medical seating requirements), GPT-5.2 reliably executes the full chain of necessary actions without breakdowns between steps.
Scientific Research Acceleration
GPT-5.2 Pro helped researchers explore an open question in statistical learning theory, proposing a proof that was subsequently verified by the authors and reviewed with external experts. The model supports:
- Literature review and synthesis across hundreds of papers
- Hypothesis generation and experimental design
- Mathematical proof exploration under human oversight
- Data analysis and statistical interpretation
On FrontierMath, an expert-level mathematics benchmark, GPT-5.2 solved 40.3% of Tier 1-3 problems, demonstrating capability for assisting with research-grade mathematical reasoning.
ChatGPT 5.2 Pricing Structure
Subscription Plans
ChatGPT Plus – $20/month:
- Access to GPT-5.2 Instant and Thinking
- Priority access during high-demand periods
- Faster response times
- DALL-E 3 for image generation
- Advanced data analysis capabilities
- Custom GPTs creation and usage
ChatGPT Pro – $200/month:
- All Plus features
- Access to GPT-5.2 Pro
- Unlimited usage of Thinking mode
- Priority compute allocation
- Early access to new features
- Sora 2 Pro for higher-quality video generation
ChatGPT Business and Enterprise:
- Custom pricing based on team size
- Admin console for user management
- Enhanced security and privacy controls
- SSO and domain verification
- Dedicated account support
- Usage analytics and insights
API Pricing
GPT-5.2 Standard (gpt-5.2):
- Input tokens: $1.75 per 1 million
- Output tokens: $14 per 1 million
- Cached input tokens: $0.175 per 1 million (90% discount)
GPT-5.2 Pro (gpt-5.2-pro):
- Input tokens: $21 per 1 million
- Output tokens: $168 per 1 million
Previous Models (For Comparison):
- GPT-5.1: $1.25 input / $10 output per 1M tokens
- GPT-5 Pro: $15 input / $120 output per 1M tokens
While GPT-5.2 costs more per token than GPT-5.1, OpenAI found that despite greater cost per token, the total cost of attaining a given quality level ended up less expensive due to GPT-5.2’s greater token efficiency in agentic evaluations.
Cost Optimization Strategies
Leverage Prompt Caching: For repeated queries with similar context, prompt caching provides 90% savings on input tokens. Structure prompts to maximize cached content by placing variable elements at the end.
Choose Appropriate Model Variants: Use Instant for routine queries, Thinking for complex work, and Pro only when maximum accuracy justifies the cost premium.
Implement Reasoning Effort Controls: Set reasoning effort parameters based on task requirements rather than defaulting to maximum for all queries.
Monitor Token Usage: Track input/output token ratios to identify opportunities for prompt optimization and response length management.
The “Code Red” Story: Why GPT-5.2 Arrived So Quickly
Google’s Gemini 3 Disruption
In November 2025, Google launched Gemini 3 Pro, which rapidly ascended to top positions on AI leaderboards including LMArena and Humanity’s Last Exam. According to former Googler Deedy Das, in the two weeks following Gemini 3’s launch, OpenAI lost nearly 6% of its visitors.
Gemini 3’s strong performance in reasoning and coding benchmarks, combined with tight integration across Google’s product ecosystem, represented the first serious challenge to OpenAI’s market leadership. User feedback suggested ChatGPT felt slower and less reliable compared to the new competition.
Internal “Code Red” Declaration
In early December 2025, OpenAI CEO Sam Altman issued an internal directive declaring “Code Red,” signaling a company-wide emergency requiring immediate, coordinated action. The directive meant:
- Reallocating engineering teams from other projects
- Fast-tracking testing protocols
- Pushing GPT-5.2’s release forward by several weeks from late December
- Postponing advertising plans to focus on core ChatGPT improvements
- Prioritizing model quality over new feature development
“We announced this code red to really signal to the company that we want to marshal resources in one particular area, and that’s a way to really define priorities and define things that can be deprioritized,” Fidji Simo, CEO of applications at OpenAI, explained.
Accelerated Development Timeline
OpenAI originally planned to release GPT-5.2 in late December 2025. Competitive pressure from Gemini 3 moved the target date to December 9, with the actual launch occurring December 11. This represented one of OpenAI’s fastest model iteration cycles, with just four weeks separating GPT-5.1 (November 13) and GPT-5.2 (December 11).
Some internal OpenAI employees reportedly requested additional development time to further refine the model, but leadership prioritized speed to market to address competitive concerns.
Strategic Implications
Sam Altman told CNBC that Google’s release of Gemini 3 had less of an impact on OpenAI’s metrics than initially estimated, and executives emphasized GPT-5.2 had been in development for many months rather than being a rushed response.
However, the timing and intensity of the release clearly reflect the increasingly competitive nature of the frontier AI market, where companies are accelerating development timelines and rapidly iterating to maintain technological leadership.
GPT-5.2 vs Claude Opus 4.5: The Third Contender
While GPT-5.2 and Gemini 3 dominate headlines, Anthropic’s Claude Opus 4.5 remains a formidable competitor, particularly for coding tasks.
Comparative Strengths
Claude Opus 4.5 Leads:
- SWE-bench Verified: 80.9% (though early results may be unstable)
- Terminal-bench 2.0: 59.3% (command-line coding proficiency)
- Industry-leading resistance to prompt injection attacks
- Web development tasks on LMArena leaderboards
GPT-5.2 Advantages:
- Superior abstract reasoning (ARC-AGI-2)
- Perfect mathematical accuracy (AIME 2025)
- Better tool integration for multi-step workflows
- More comprehensive long-context handling
- Lower API pricing
Market Positioning
Claude Opus 4.5 appeals to developers prioritizing code quality and security, particularly for web applications. GPT-5.2 targets broader professional knowledge work and enterprise applications. Organizations may benefit from a hybrid approach, selecting models based on specific task requirements rather than committing exclusively to one provider.
Limitations and Known Issues
Despite significant improvements, GPT-5.2 remains imperfect. OpenAI acknowledges several limitations:
Factual Accuracy Gaps
While error rates dropped 30% relative to GPT-5.1, GPT-5.2 still produces errors in 6.2% of responses. For critical decisions, OpenAI recommends double-checking answers against authoritative sources. Claim-level error rates are lower than response-level rates since most responses contain multiple claims.
Reasoning Mistakes
The model occasionally makes mistakes that appear to be errors of internal simulation rather than physics violations. For example, in some scenarios, it may incorrectly model agent behavior or environmental dynamics, though these errors are less frequent than in previous systems.
Context Window Constraints
While GPT-5.2 handles up to 256,000 tokens effectively, tasks benefiting from thinking beyond this limit require workarounds. The Responses /compact endpoint extends effective context windows for tool-heavy, long-running workflows.
Speed-Quality Tradeoffs
GPT-5.2 Pro prioritizes accuracy over speed, with generation times sometimes extending to several minutes for comprehensive analyses. Users requiring real-time responses should use Instant or Thinking variants with appropriate reasoning effort settings.
Incomplete Multimodal Capabilities
Unlike Gemini 3’s unified text-vision-audio architecture, GPT-5.2 requires integration with separate systems (DALL-E 3 for images, Sora 2 for video). This fragmentation adds complexity for applications requiring seamless multimodal generation.
Future Roadmap and What’s Next
Codex Optimization Coming Soon
OpenAI expects to release a version of GPT-5.2 optimized for Codex in the coming weeks. This specialized variant will further enhance coding capabilities for developers using OpenAI’s development tools.
GPT-6 Timeline Implications
The rapid GPT-5.2 release raises questions about GPT-6’s development schedule. OpenAI has historically followed roughly annual cycles for major model generations (GPT-3, GPT-4, GPT-5). The compressed timeline from GPT-5.1 to GPT-5.2 suggests the company may continue iterative 5.x releases while working on the next-generation architecture codenamed “Garlic.”
Industry analysts expect GPT-6 development to focus on:
- Further scaling of reasoning capabilities
- Enhanced multimodal integration
- Improved few-shot learning and generalization
- Reduced computational requirements
- Stronger alignment with human preferences
Enterprise Feature Expansion
OpenAI plans to expand enterprise-focused capabilities including:
- Enhanced analytics dashboards for usage tracking
- More granular access controls and permission management
- Improved audit logging for compliance requirements
- Tighter integration with Microsoft 365 and Azure services
- Custom model fine-tuning options for large organizations
Continued Safety Research
The company commits to ongoing work on:
- Further reducing hallucinations and factual errors
- Calibrating refusal behavior to minimize false positives
- Expanding age verification systems globally
- Developing better tools for detecting AI-generated content
- Improving model interpretability and transparency
Frequently Asked Questions (FAQ)
What is the difference between ChatGPT 5.1 and 5.2?
GPT-5.2 delivers 30% fewer errors, 80% accuracy on software engineering benchmarks (up from 76.3%), and 100% on AIME 2025 math problems (up from 94%). The model features enhanced multimodal understanding, faster processing with adaptive reasoning, improved memory that learns preferences more quickly, and expanded tool access. GPT-5.1 had “High” reasoning depth while GPT-5.2 has “Higher” depth, translating to more reliable outcomes for complex analytical tasks.
Is GPT-5.2 better than Gemini 3?
GPT-5.2 outperforms Gemini 3 on coding benchmarks (SWE-bench Pro: 55.6% vs 43.3%), abstract reasoning (ARC-AGI-1: 86.2% vs 75%), and mathematical accuracy (AIME 2025: 100% vs 95%). Gemini 3 leads on multimodal tasks (MMMLU: 91.8% vs 89.6%) and offers broader product ecosystem integration. The “better” model depends on your specific use case: choose GPT-5.2 for professional knowledge work and coding, Gemini 3 for heavy image/video workflows and Google Workspace integration.
How much does ChatGPT 5.2 cost?
ChatGPT Plus subscribers ($20/month) get access to GPT-5.2 Instant and Thinking variants. ChatGPT Pro ($200/month) includes GPT-5.2 Pro. For API access, GPT-5.2 costs $1.75 per million input tokens and $14 per million output tokens, with a 90% discount on cached inputs ($0.175 per million). GPT-5.2 Pro API pricing is $21 input / $168 output per million tokens.
Can I still use GPT-5.1?
Yes. ChatGPT paid users can access GPT-5.1 for three months through the legacy models dropdown, after which OpenAI will sunset GPT-5.1 in the ChatGPT interface. In the API, OpenAI has no current plans to deprecate GPT-5.1, GPT-5, or GPT-4.1, and will communicate any deprecation plans with advance notice for developers.
What does GPT-5.2 benchmarks mean?
Benchmarks are standardized tests measuring AI model performance across specific tasks. SWE-bench evaluates software engineering on real-world code repositories. GPQA Diamond tests graduate-level scientific knowledge. ARC-AGI measures abstract reasoning ability. GDPval assesses professional knowledge work across 44 occupations. Higher benchmark scores indicate better performance, but real-world effectiveness also depends on task-specific requirements an
Is ChatGPT 5.2 available for free?
GPT-5.2 began rolling out to paid subscribers (Plus, Pro, Go, Business, Enterprise) starting December 11, 2025. Free tier access timeline has not been announced. Historically, OpenAI makes frontier models available to free users several months after paid release, but GPT-5.2 may remain paid-only longer due to compute costs.
Does GPT-5.2 have internet access?
GPT-5.2’s knowledge cutoff is January 2025, meaning training data extends through that date. For current information beyond January 2025, ChatGPT Plus and Pro users can enable web browsing tools to search and retrieve real-time information. API users can implement similar functionality through function calling and web retrieval tools.
What is “adult mode” in ChatGPT?
“Adult mode” (initially planned for December 2025, delayed to Q1 2026) will allow users 18+ to opt into less restrictive content filters for creative writing, mature discussions, and nuanced topics where default safety systems may be overly cautious. The feature requires robust age verification to prevent teen access, which OpenAI is still refining.
How do I access GPT-5.2 in the API?
Use model identifier gpt-5.2 for GPT-5.2 Thinking, gpt-5.2-chat-latest for GPT-5.2 Instant, or gpt-5.2-pro for GPT-5.2 Pro. All models are available now through OpenAI’s API platform for developers with active accounts. Set the new xhigh reasoning effort parameter for maximum quality when needed.
Does GPT-5.2 replace GPT-4?
No. OpenAI continues supporting GPT-4.1 in the API with no deprecation plans announced. Many applications optimized for GPT-4’s behavior may prefer to remain on that model until testing confirms GPT-5.2 provides equivalent or better results for their specific use cases.
Can GPT-5.2 generate images and videos?
GPT-5.2 focuses on text generation, code, and reasoning. For images, ChatGPT integrates DALL-E 3. For video generation, users must access Sora 2 through the separate Sora app (iOS) or sora.com. Unlike Gemini 3’s unified multimodal architecture, OpenAI maintains specialized models for different media types.
What is the difference between GPT-5.2 Instant, Thinking, and Pro?
Instant optimizes for speed on everyday tasks like information queries, translations, and basic writing. Thinking engages deeper reasoning for complex coding, document analysis, and multi-step problem-solving, adapting time spent based on question difficulty. Pro maximizes accuracy for critical decisions and difficult technical questions, trading speed for highest-quality outputs. Choose based on your urgency-accuracy tradeoff.
Does ChatGPT 5.2 work with plugins?
OpenAI deprecated the original ChatGPT plugins in March 2024, replacing them with GPTs (custom AI assistants) and API function calling. GPT-5.2 works with GPTs and supports enhanced tool calling for API developers, enabling integration with external services, databases, and enterprise systems.
How accurate is GPT-5.2 for factual information?
GPT-5.2 produces errors in 6.2% of responses on representative ChatGPT queries (down from 8.8% for GPT-5.1), but “errors” include any inaccuracies across multi-claim responses. For critical decisions in legal, medical, financial, or safety contexts, always verify outputs against authoritative sources. The model should augment rather than replace expert human judgment.
Can GPT-5.2 write code better than Claude or Gemini?
On SWE-Bench Pro, GPT-5.2 scores 55.6%, outperforming Gemini 3 (43.3%) but trailing Claude Opus 4.5’s early reported results (80.9%, though subject to verification). For terminal commands, Claude Opus 4.5 leads at 59.3% on Terminal-bench 2.0. No single model universally dominates coding; choice depends on specific language, framework, and complexity requirements.
When will GPT-6 be released?
OpenAI has not announced GPT-6 release dates. Based on historical patterns (GPT-3: 2020, GPT-4: 2023, GPT-5: late 2024), the next major architecture revision might arrive late 2025 or early 2026. However, the rapid GPT-5.1 to GPT-5.2 iteration suggests OpenAI may continue incremental 5.x releases while developing GPT-6 in parallel.
Is GPT-5.2 ChatGPT’s “smartest” model?
Yes, GPT-5.2 Pro represents OpenAI’s most capable publicly available model as of December 2025. It surpasses GPT-5.1 Pro and all previous ChatGPT iterations on comprehensive benchmark suites. However, “smartest” depends on task type—Claude Opus 4.5 may excel for certain coding workflows, while Gemini 3 leads on some multimodal benchmarks.
Conclusion
GPT-5.2 represents OpenAI’s most significant iterative model release, delivering expert-level performance on professional knowledge work while maintaining competitive pricing and accessibility. The model’s 70.9% win rate against industry professionals on GDPval, combined with 80% accuracy on software engineering tasks and perfect scores on AIME 2025 mathematics problems, establishes new benchmarks for AI-assisted productivity.
For developers, data analysts, researchers, and enterprise professionals, GPT-5.2 offers meaningful improvements in reliability, reasoning depth, and tool integration that translate directly into time savings and quality gains. Organizations already invested in the OpenAI ecosystem will find the transition seamless, with backward compatibility maintained across API versions and gradual rollout minimizing disruption.
The competitive landscape remains dynamic, with Gemini 3 excelling in multimodal tasks and Claude Opus 4.5 leading in specific coding benchmarks. Rather than declaring a single winner, the market is evolving toward specialized model selection based on task requirements, with organizations maintaining relationships with multiple AI providers to optimize for different workflows.
As frontier AI models continue rapid improvement cycles, GPT-5.2 demonstrates that the path to AGI involves not just architectural breakthroughs but also careful refinement of reasoning capabilities, factual accuracy, and practical reliability for real-world professional applications. The December 2025 release marks another step in OpenAI’s mission to ensure artificial general intelligence benefits all of humanity—starting with making knowledge workers more productive, creative, and effective in their daily work.